Why AI Agents Fail in Production
Most agent projects stall before production, and the model is rarely the cause. The four failure modes behind it: durability, security, cost, and observability.
Jani Janakiram, MSV
Guest Author
The AI agent market has produced thousands of demos and very few production deployments. You have probably sat through some of the demos. An agent reads a support ticket, queries three systems, drafts a refund, and books a follow-up, all in ninety seconds on a stage. It looks finished. Then the same agent goes nowhere for six months, sitting in a staging environment while the budget burns and someone in engineering keeps getting asked why the rollout slipped again.
The numbers behind that pattern are not subtle. Gartner predicted in June 2025 that more than 40 percent of agentic AI projects will be canceled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls. A 2025 S&P Global Market Intelligence survey of more than 1,000 enterprises found that the average organization scrapped 46 percent of its AI proofs of concept before they reached production, with the share of companies abandoning most of their AI initiatives rising from 17 percent in 2024 to 42 percent in 2025. MIT's NANDA initiative, in its 2025 study drawing on more than 300 public AI deployments, found that only around 5 percent of integrated pilots showed measurable impact on the bottom line.
It would be easy to read those figures as a verdict on the technology. The models are not good enough yet, the reasoning is not reliable, the agent's step planning needs another iteration. That reading is incomplete, and acting on it is expensive, because it sends teams back to tune the one part of the system that was already working. Production failures have many causes, including unclear use cases, weak data access, integration debt, and regulatory friction. The model still matters, but in production it is only one part of the system. The recurring pattern this blog series is about is narrower and more fixable than any of those. Teams build agent behavior before they have the infrastructure to recover it, govern it, observe it, and pay for it predictably.
Why the demo works and production does not
A demo agent has one job. Complete the task. It runs on a clean machine, with a network that stays up, against a tool that returns what it should, watched by the person who built it. Nothing in that environment tests what happens when conditions are not perfect, because the demo was designed so they always are.
A production agent lives somewhere else. The pod it runs on gets rescheduled. The LLM provider rate-limits it halfway through a fifty-step workflow. The database it calls is briefly unreachable. A security reviewer wants to know which agent touched the payments API last Tuesday and on whose authority. Finance wants to know why last month's token bill was double the forecast. None of those questions are about whether the agent can reason. They are about whether the agent can recover, prove who it is, stay inside a budget, and account for what it did.
If that gap sounds familiar, it should. Enterprise teams crossed a version of it before, when applications moved from a developer's laptop into shared production. Code that ran fine in isolation fell over once it had to handle restarts, scaling, service discovery, and failure, and the fix was an infrastructure layer rather than better application code. Kubernetes became the place that layer lived. Agents are at the same point on the same curve, where the framework decides what the agent does and something underneath has to make that behavior survive the real world.
Four things break when an agent makes that crossing without a platform underneath. They are worth naming precisely, because the rest of this series is organized around them.
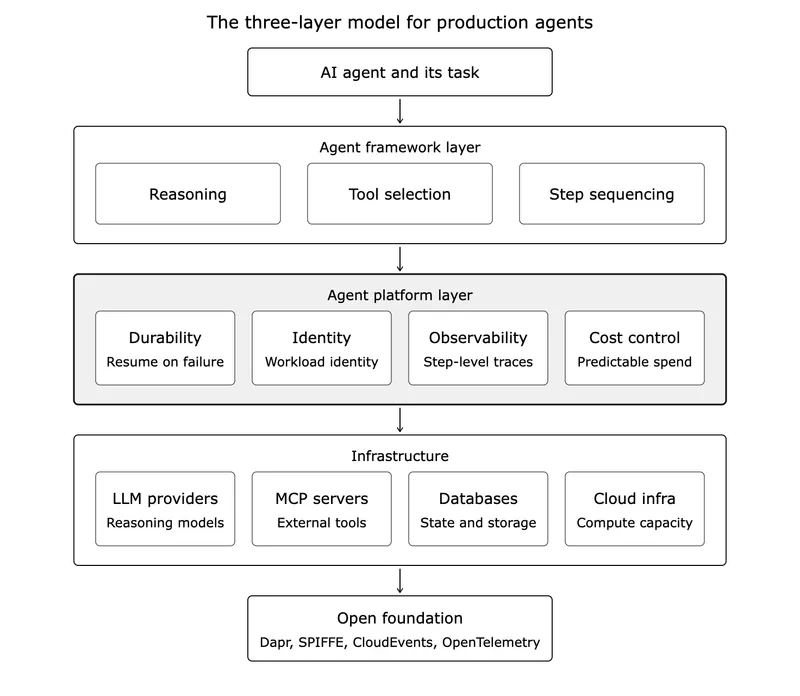 A production agent is a three-layer stack. The framework decides what the agent does. The agent platform underneath makes that behaviour durable, secure, observable, and economical. Below sits the infrastructure the agent ultimately reaches, and the whole thing runs on an open foundation.
A production agent is a three-layer stack. The framework decides what the agent does. The agent platform underneath makes that behaviour durable, secure, observable, and economical. Below sits the infrastructure the agent ultimately reaches, and the whole thing runs on an open foundation.
Failure mode one: durability
Durability: the property that lets a workflow survive a failure and resume from where it stopped, rather than starting over.
Most demo-stage agents do not have durability provided by the platform underneath them. Some frameworks ship pieces of it themselves, a checkpointer here, a memory store there, but those pieces are framework-specific, often cover only the conversation context rather than the full workflow trace, and depend on how the agent was written. Move the agent to a different framework, or write it without that feature configured, and the durability goes with it.
It helps to be precise about what an agent task actually needs to keep safe across a crash, because two different things are usually bundled under the word "memory." The first is the agent's working context, the conversation, the reasoning state, the system prompt, the chat thread, everything the LLM relies on to know where it is in the discussion. The second is the workflow record, the durable trace of which steps have already started, which have completed, which tools have already been called, and what those tools returned. A demo-stage agent typically keeps both in process memory. When the process dies, and processes die routinely in production for reasons that have nothing to do with the agent, both go with it. The agent comes back up with no record of the conversation and no record of the work already done, and it starts again from step one.
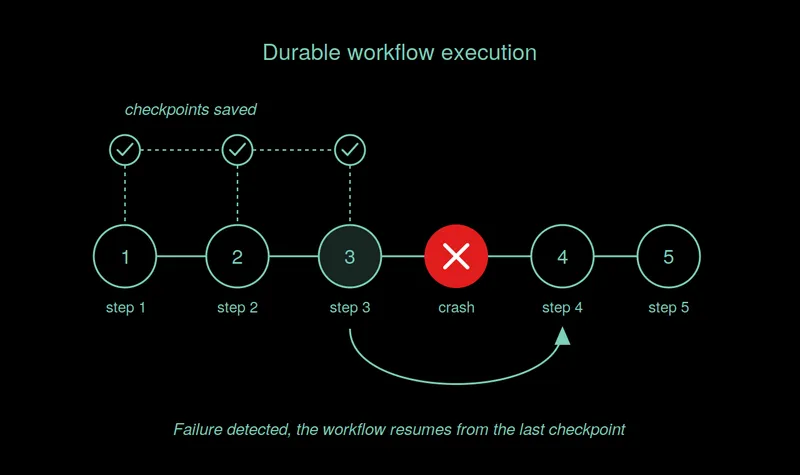
Consider an agent that is forty-seven steps into a fifty-step reconciliation job when its pod is evicted. Without durability, the next run does not resume at step forty-seven. It repeats all forty-seven steps, calls the same tools again, and pays for the same LLM tokens a second time. Because each of those earlier steps did real work that cannot be undone, sent an email, posted a ledger entry, charged a card, the rerun risks doing all of it a second time. The agent reasoned fine. It failed because nothing was keeping track of what it had completed so far.
Failure mode two: security
In production, an agent calls APIs, reads databases, invokes tools, and sometimes spins up other agents. Each of those actions is a privileged operation. In most deployments today, the agent performs them using a shared static credential, an API key copied into an environment variable, with no identity of its own and no record of which agent used it for what.
Security teams have a name for this and a long history of disliking it. A shared secret leaves three questions unanswered, and they are the questions a security team has to be able to answer for every privileged action that runs in production. Who is the agent? What is it authorized to do? What has it actually done? With a static API key sitting in an environment variable, the answers are none, anything the key can reach, and nobody knows. The agent is, from the security team's point of view, an anonymous process holding a key. That was tolerable when the key unlocked one read-only reporting endpoint. It stops being tolerable when the agent can move money, change records, or hand work to another agent that inherits the same blank check.
Picture a procurement agent that calls a payment tool. The control a security team actually wants is conditional. The agent should be able to invoke that tool only if a prior fraud-check step ran and passed. A shared API key cannot express that. The key either works or it does not, and it carries no memory of what happened earlier in the workflow. The agent could skip the fraud check, call the payment tool, and the credential would not notice. Closing that gap needs the agent to have something more like a passport than a key. A verifiable identity that belongs to the agent, attached to the workflow, with authorizations that other steps can check, and a record of where it has been and what it has done. Most agent stacks do not give the agent one.
Microservices solved a version of this problem fifteen years ago. Static API keys gave way to workload identity, mutual TLS, and zero-trust authorization, and the credential sprawl that came before that shift is what nobody wants to repeat. Agents are now in the same place microservices were before those tools existed, and the fix follows the same shape. The Diagrid blog on Agent Identity walks through that parallel in detail.
Failure mode three: cost
LLM calls cost money on every invocation, and an agent's spend is hard to predict because the agent decides at runtime how many calls to make. A finance team that can forecast compute to within a few percent often cannot forecast agent token spend within a factor of two.
Failure makes the math worse. When a workflow without durability restarts, every token it already spent is spent again, and that double-billing does not show up as a separate line item. It hides inside a total that looks merely higher than expected. In scenarios where an early deployment sees 15 or 30 percent of its workflows fail, a team can be paying a sizable share of its LLM bill to redo work it already paid for once. The cost problem and the durability problem are the same problem seen from the finance side of the house.
Two more cost levers go missing for the same reason. Agents repeat near-identical LLM calls constantly, and without a caching layer in front of the provider, every repeat is billed at full price. And an agent wired directly to one provider's API is hard to move, so when a cheaper or faster model appears, the switch turns into an application rewrite rather than a configuration change. None of this is visible in a demo, because a demo runs once, on one provider, and nobody is reading the invoice. It becomes visible the first month finance asks why the forecast was wrong, and the answer has to come from a platform that recorded where the money went.
A fourth lever sits behind those three, and it is the hardest to pull. Once a team can see every step an agent actually took during a run, the LLM calls, the retries, the context payloads, the convergence loops, they can start asking which of those steps the agent did not need to take at all. A retry storm that nobody noticed. Five reasoning iterations to settle a question the first one already answered. A 50k-token context window when a 2k slice would have done. Each of those is real money, and most of them are invisible until a person looks at the trace and decides what should not have happened. Tools can surface the evidence. Judgment turns it into savings. That is the lever that compounds, because every fix gets applied across every future run.
Failure mode four: observability
When an agent does something unexpected at two in the morning, the operations team needs to be able to answer one question by breakfast. What happened? With most agent deployments, they cannot.
Traditional application monitoring assumes a request-response shape. A call comes in, a response goes out, and the trace covers the span between them. An agent workflow does not have that shape. It is a non-deterministic sequence of reasoning steps, tool calls, and LLM exchanges, and a monitoring tool built for request-response captures almost none of what matters inside it. The team is left reconstructing the incident from scattered logs, guessing at which step the agent took a wrong turn, and is often unable to reproduce the run at all. Reconstruction after the fact takes days, and sometimes it simply does not converge.
Why the platform you already have does not cover this
A reasonable objection at this point is that enterprises are not short of infrastructure. There are API gateways, network policies, identity providers, and observability platforms already in place. Why does an agent need something new?
Because each of those tools was built for a deterministic, request-response world, and it does its job well in that world. An AI/MCP gateway routes and rate-limits traffic. It was not designed to give a workflow a durable identity or to attest that a fraud check ran before a payment step. A network policy controls which services can reach which other services. It does not know that an agent calling a tool is a different trust question from a microservice calling an API. An application performance monitor assumes the request-response span that agent workflows do not have. These tools are not failing. They are aimed at a different target.
Agent frameworks sit on the other side of the same gap. LangGraph, CrewAI, the Microsoft Agent Framework, Google's ADK, and the rest are good at what they are for. They define how an agent reasons, which tools it can reach, and how steps connect. That is the behavior layer, and it is genuinely useful. Some frameworks also ship pieces of the production story, a checkpointing option here, a tracing integration there, an orchestration construct elsewhere. What they usually do not provide is a single, framework-agnostic layer underneath them all that makes agent behavior durable across a crash, governed by a verifiable identity, observable at the step level, and economical at scale. Those pieces stay fragmented, specific to one framework, and not enforced consistently as infrastructure properties.
Teams that hit this gap often try to fill it by stitching pieces together, a workflow engine here, an identity provider there, a custom observability shim, a caching proxy, and glue code to hold the assembly together. That assembly is itself a platform build, and it is one of the more demanding ones, asking a team hired to ship agents to also become an in-house systems integrator. The time spent on the assembly is time not spent on the agents themselves.
So the picture is three layers, not one. The framework defines what the agent does. The agent platform underneath makes that behavior reliable, governed, observable, and economical. The platform itself runs on infrastructure, the databases, MCP servers, LLM providers, and cloud capacity the agent ultimately reaches. Teams that ship agents to production have all three working together. Teams stuck in the pilot loop usually have only the first, and they keep tuning it because it is the layer they can see.
What the rest of this series covers
This is the layer Diagrid Catalyst provides. Catalyst is the production platform that agents are missing, and it is built on an open foundation, the Dapr runtime, a graduated project of the Cloud Native Computing Foundation, together with open standards for identity (SPIFFE), telemetry (OTEL), and messaging (Cloud Events). The open foundation matters for a reason this post has already touched. Kubernetes won the last infrastructure transition because it was open and enterprises could control it, and upcoming posts in this series returns to that history in detail.
If you want to go deeper into the four failure modes before the next post, four pieces from the Diagrid blog cover most of the ground.
On durability, From Deterministic to Agentic, Creating Durable AI Workflows with Dapr walks through the runtime primitive that lets an agent resume mid-workflow.
On security, Agent Identity, The Foundational Layer that AI Is Still Missing frames identity as the workload problem agents inherit from microservices, and MCP Gateways Aren't Enough shows where routing-only security leaves a hole.
On observability, You Deployed Your Agents. Now What? covers debugging non-deterministic agents once they reach production.
The remaining chapters take the four failure modes apart one at a time and show what closing each one actually requires. The next post in 2 weeks starts where the cost of failure is highest and the fix is most concrete, with durable execution, the runtime primitive that lets an agent survive a crash at step forty-seven and resume at step forty-seven.


