The Economics of Running AI Agents at Scale
Agent spend is set at runtime by the agent's own decisions. See how per-task records in Diagrid Catalyst let a finance team model and bound the cost of running agents.
Jani Janakiram, MSV
Guest Author
The first post in this series named four ways production agents fail: durability, security, cost, and observability. The second took durability apart and showed how a runtime that replays a crashed workflow brings a stalled agent back to the step where it stopped. It closed on a line worth picking up here. Durability preserves the work and lets a crashed run finish, but it does not control the cost of that run. Cost is the same problem described in the second post, read from the finance side of the house.
A demo never surfaces the bill. It runs once, on one provider, against tools that answer on the first try, and nobody opens the invoice afterward. Production is where the invoice arrives, and it tends to arrive larger and less predictable than the forecast, because an agent decides at runtime how many model calls to make. A finance team that can forecast compute to within a narrow band often cannot bound an agent's token spend the same way. This post is about giving that finance team the pieces to model the spend itself, rather than a single number to trust.
"The thing that makes agent cost different from any prior workload: it's set at runtime by the agent's own decisions, not at design time. You can't size it from the architecture diagram. So almost everything is about bounding nondeterministic spend. That is much harder."
The unit economics of a single task
Start with one task and follow the money. The running example through this series is a small support agent that works a refund ticket in five stages: classification, account retrieval, drafting the refund, customer notification, and closing the case. Each stage does a piece of real work, and each carries a cost that a finance team can name once someone lays out the stages.
Three cost drivers sit behind that single run:
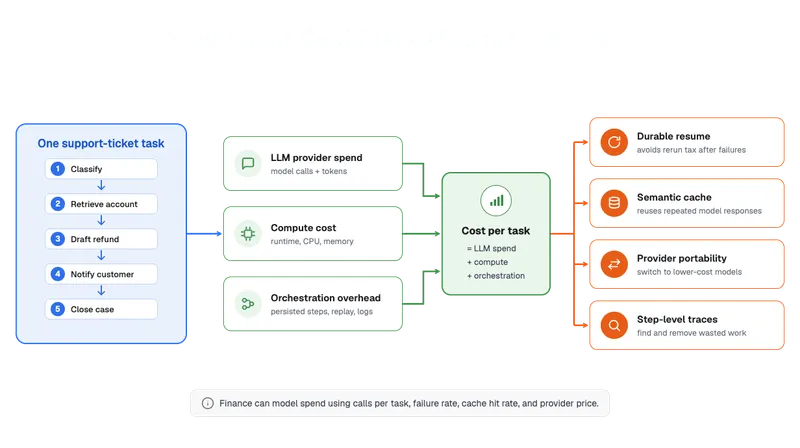
The first driver is LLM provider spend. Every reasoning step and every drafting step sends tokens to a model provider and pays for the tokens that come back. This is usually the largest line and the hardest to bound, because the agent decides at runtime how many calls to make. A ticket the agent clears in one pass costs less than one where it loops back for another model call. Which kind a given ticket turns out to be is only known once the agent runs it.
The second driver is compute: the CPU and memory the agent process holds while the task runs. A synchronous tool call can hold worker resources while it waits for a response. Durable waits behave differently, since a workflow paused on a timer or an external event can resume later without holding a thread for the whole wait. Compute is steadier than model spend and easier to forecast, because it tracks how long tasks run and how many run at once.
The third driver is orchestration overhead, the cost of persisting each step to a state store, replaying history on recovery, and writing the trace. On many LLM-heavy workloads this is smaller than the model spend, but it is workload-dependent, and a high-frequency, low-token agent can carry nontrivial state and logging cost relative to its model bill. A team should measure it from its own traces and retention settings rather than assume it away. It is the price of the durable record, and the later levers in this post are paid for out of what that record makes possible.
| Cost driver | What it scales with | How a finance team bounds it |
|---|---|---|
| LLM provider spend | Number and size of model calls, set at runtime by the agent | Cap reasoning loops and context size, cache near-duplicate calls, read calls-per-task from the trace |
| Compute | Task duration and concurrency | Right-size the workload and scale it to demand, since this line is steadier than model spend |
| Orchestration overhead | Steps persisted and replayed per run | Measure it from your own traces and retention settings, since on LLM-heavy workloads it is usually smaller than model spend |
The breakdown matters less than what it enables. Each driver becomes a variable that a finance team can set once the platform records it for each task. Without that record the three collapse into one unpredictable total, and the only honest forecast is a wide range. Catalyst's workflow history, API logs, and Conversation API token counts give teams the raw record they need to separate model usage, workflow duration, and orchestration activity by task.
Those three drivers each compute on their own line, and the task cost is their sum, so a finance team can populate it from its own trace. The form below is simplified, and it ignores provider-specific discounts, cached-token pricing, and tiered rates.
cost_per_call =
(avg_input_tokens / 1_000_000) × input_price_per_million
+ (avg_output_tokens / 1_000_000) × output_price_per_million
llm_spend = model_calls × cost_per_call # LLM provider spend
compute_cost = workflow_runtime × compute_rate # compute
orchestration_cost = persisted_steps × storage_write_cost # orchestration overhead
cost_per_task = llm_spend + compute_cost + orchestration_costEvery term on the right is a value a team already knows or can read from the record. The platform supplies the measured inputs, and the finance team supplies the prices and runs the arithmetic for its own scale.
Walk the refund agent's five stages, and each driver lands on specific steps. Classification and drafting are model calls, so they carry most of the token spend. Account retrieval, notification, and the closing write are tool calls against internal systems, cheap on tokens but still holding worker resources while they wait on a response. A finance team reading the trace can see that two of the five stages drive the model bill, which is where any caching or loop-capping effort pays off first. That is the difference a per-task record makes. It tells you which stage to attack before you spend a week optimizing one that was never the problem.
The cost of failure
Now let the task fail partway through, because it will in production. The pod gets rescheduled, the provider rate-limits the agent mid-run, a database is briefly unreachable. The second post covered what that does to the work. Here the same event shows up as money.
When a workflow without durable execution restarts, it does not resume from where it left off. It begins again at step one, calls the same tools again, and pays for the same model tokens a second time. The financial consequence is that this double-billing never appears as a line item. It hides inside a total that looks merely higher than the forecast, which is the worst place for a cost to sit, because nobody goes looking for a charge they cannot see.
The size of that hidden charge tracks how often workflows fail. At a low failure rate, it is a rounding error. The first post in this series put the illustrative band at 15 to 30 percent of workflows failing in an early, under-hardened deployment, and at that range the rerun tax stops being a rounding error. Hold the model spend of a clean run at one unit. The wasted spend is then a function of the failure rate and the average point of failure, because a workflow that restarts from zero re-bills the steps it had already completed.
| Workflow failure rate (illustrative) | Restart from zero, model spend repeated | Durable resume, model spend repeated |
|---|---|---|
| 5% | Up to about 5% of clean-run model spend, scaled by how far failed runs had progressed | Usually limited to the in-flight or unrecorded step |
| 15% | Up to about 15%, before progress weighting | Usually limited to the in-flight or unrecorded step |
| 30% | Up to about 30%, before progress weighting | Usually limited to the in-flight or unrecorded step |
The exact figure depends on where in a run the failures land, because a run that dies at its last step wastes more than one that dies at its first. The table shows illustrative upper bounds rather than expected waste, since most failed runs die before completing all their paid work. Restart from zero sets the ceiling on that rerun tax, while durable resume limits the repeat to the in-flight or unrecorded step. The cost problem and the durability problem are one problem counted in different units.
A finance team will reasonably ask whether the tools already in place handle this, and mostly they do not. A retry re-runs a failed step, which does nothing for steps that finished before the crash, leaving the double-billing untouched. A checkpoint saves state to reload later, but something still has to detect that the process died and decide to reload it; that detection is the part that is missing. Neither closes the cost leak on its own, because the leak comes from finished work being repeated rather than from a single step failing.
Avoiding that charge depends on the runtime owning the entire failure lifecycle, detecting when execution stopped, recovering the persisted history, and resuming at the next live step. Detection is the part most stacks skip, because a checkpoint or a retry assumes someone already knows the run died. Durable execution on Dapr, the runtime used in Catalyst, solves all three. It detects the interruption, replays the append-only history so that steps that have already completed return their stored results rather than running and billing again, and resumes at the step that has not finished. In the refund example, the classify and retrieve stages are returned from the persisted record. Only the stage that was in flight when the process died runs again.
That last point is where a finance reader needs one piece of precision an engineer would insist on. Durable execution stops you paying twice for steps that are already completed. It does not, on its own, make the interrupted step safe to repeat. If that step charged a card or posted a ledger entry before the crash and the runtime had not yet recorded the result, recovery can rerun the side effect. Idempotency keys or an outbox pattern are what keep the retry from issuing a second refund. Durability keeps the receipts for finished work, while idempotency protects the one piece of work that was interrupted. A team needs both, because they solve different halves of the cost-of-failure problem.
Caching the calls you already paid for
Failure is one source of repeated spend. Repetition is the other, and it is quieter. Agents send near-identical model calls all day. The same kind of ticket produces the same kind of classification prompt, worded a little differently each time, and without a cache in front of the provider, every near-duplicate is billed at full price.
A semantic cache sits in front of the model, and answers repeated requests with a stored response instead of making a fresh call. This is a real cache of model responses, worth keeping distinct from the replay described above. Replay returns the result of a step from the workflow's persisted history during recovery. A semantic cache returns a model response that an earlier run already paid for, matched on meaning rather than exact wording. Different mechanisms, different jobs, both cutting spend on calls a team would otherwise buy twice.
How much it saves depends on how repetitive the traffic is. For the cacheable share of calls, the reduction in provider spend tracks the cache hit rate because every hit is answered from storage instead of paying for a fresh call. An agent handling a narrow, high-volume task with many near-duplicate prompts earns a high hit rate, while an agent fielding wildly varied one-off requests earns little, because there is nothing to reuse.
| Cache hit rate on cacheable calls (illustrative) | Approximate reduction in provider spend on those calls |
|---|---|
| 25% | About a quarter of the cacheable calls avoided |
| 50% | About half avoided |
| 70% | The high end Diagrid documents, against repeated queries on unchanged content |
Diagrid's healthcare materials put the documented ceiling at a 70 percent reduction in LLM spend. That figure assumes a workload that runs the same queries on unchanged content many times a day. A prior-authorization agent doing repeated clinical-guideline lookups is the kind of case that reaches it. While most calls are repeated semantic queries against unchanged content, the saving approaches that ceiling on total LLM spend, whereas a workload with only a minority of cacheable calls saves far less overall. A finance team should read the 70 percent as the top of a range it can measure on its own traffic, not a figure to drop into a forecast. Diagrid describes Catalyst's semantic caching as a built-in, data-plane capability that works across providers, avoids the provider call on a cache hit, and is not bound to a short expiry, so the lever is there without a team standing up a caching proxy of its own.
One caution travels with this lever. A cache that answers from meaning rather than exact wording can return a response that fits the words but not the case. For a refund agent, account-specific or case-specific prompts may not belong in the semantic cache at all, since caching is safer for reusable policy, classification, or guideline lookups than for customer-specific actions. The similarity threshold and the decision about what to cache are settings a platform team owns, and they are worth getting right before the savings are counted, because a cache tuned for cost alone can trade an incident for a discount.
Provider choice as a cost lever
The third external lever is the freedom to change providers. An agent wired directly into one provider's API is expensive to move, so when a cheaper or faster model arrives, the switch becomes an application rewrite rather than a setting change. That is the same lock-in shape enterprises learned to design out of earlier infrastructure, where being tied to one vendor's interface quietly set the price of leaving.
GitHub made that lock-in concrete in June 2026. It moved Copilot from a flat monthly subscription to usage-based billing metered by tokens consumed. The price point did not move, but it now bought a fixed allowance of credits rather than unlimited use, and the agentic workloads that read context and loop over a codebase burned through that allowance first. Community projections put the new bill at ten to fifty times the old one for the heaviest users. GitHub also pulled the fallback that once dropped an exhausted user to a cheaper model, so a team watching the new bill had two ways to respond: change models or move the work. The teams wired most tightly to a single provider had the least room to do either.
Catalyst routes model calls through the Dapr Conversation API, a unified abstraction between the agent and the provider. The same agent logic targets that API, while the provider-specific details are handled in the component configuration. In the infrastructure layer, switching providers is a 5 min component-configuration change rather than an application rewrite, though a team still has to validate prompts, outputs, latency, and model behavior before a production cutover. Current Diagrid docs list supported Conversation providers including OpenAI, Anthropic, AWS Bedrock, Google AI, Mistral, DeepSeek, Hugging Face, and Ollama. For a finance team, that turns provider pricing into something negotiable, because the cost of moving is no longer a funded application migration.
The lever that compounds
The first three levers cut the cost of work the agent had to do. The last one cuts the work it never needed to do, and it is the lever that keeps paying back, because every fix lands on every future run.
Once a platform records every step a run took, the model calls, the retries, the context payloads, the reasoning loops, a team can read a real trace and ask which steps earned their place. The trace surfaces a retry storm nobody noticed, several reasoning iterations spent settling a question the first one had already answered, or an oversized context window where a small slice would have served. Each of those is real money, and most remain invisible until someone reads the trace and decides what should not have happened. The tooling surfaces the evidence, and judgment turns it into savings that recur on every subsequent run.
Step-level execution records and per-call token counts also serve a second role: attribution. Once those records are joined with provider prices and tenant or workflow identity, teams can derive spend by agent, by workflow, and by tenant, which is what chargeback, showback, and forecasting need to work at all.
Uniphar already runs the pattern in production. It uses Dapr workflows to automate Azure cost attribution across more than 400 workflows, each resuming from its last saved checkpoint after a failure rather than restarting. No agents run anywhere in that system. The same workflow history that lets an agent platform meter spend by step also lets a cost-tracking application attribute spend precisely, which is why a failure mid-run does not corrupt the numbers.
Finance, engineering, and security end up reading the same record rather than three reconstructions that disagree with each other. A forecast built on per-task measurement holds up in a budget review in a way that a single blended estimate does not.
What a finance team should ask
Four questions tell a finance or procurement team whether a platform can support that kind of model.
1) Visibility: Can we see calls per task or only a monthly total?
2) Failure cost: Does the platform measure how much spend goes to reruns, and does it prevent those reruns from being billed twice?
3) Cache effectiveness: Can we measure the hit rate on our own traffic rather than accept a quoted figure?
4) Model portability: What does switching a model cost in practice, a configuration change or a rewrite?
A platform that cannot answer the first question leaves every other answer to guesswork, because none of the levers can be modeled until the spend is visible per task.
Where this leaves the finance team
Put the four levers together and the shape of the answer changes. Agent spend stops being one unpredictable number and becomes a model with inputs a finance team owns: calls per task, failure rate, cache hit rate, provider price, and the steps that should never have run. Catalyst does not hand finance a composite cost figure to trust, and it should not, because the right number depends on a team's own traffic and tolerance for failure. What it hands them is the record to build that number themselves, and the controls to act on what the record shows.
There is a second reason that record matters, and it points straight at the next post. A finance or audit team in a regulated sector not only needs the spending broken down, but also needs to prove that the breakdown was not edited after the fact. Dapr 1.18 added that proof to the same workflow history this post has leaned on, signing each step with a SPIFFE identity so the execution record is tamper-evident and independently verifiable. Durable execution keeps the record, while verifiable execution makes it defensible in an audit. For fintech and healthcare, where Uniphar already runs, that distinction is the whole point.
The next post in the series turns to the failure mode a security team owns, identity. If the cost story is about proving where the money went, the security story asks a different question, who the agent was when it acted, and whether it was allowed to act at all.
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.


