Durable Execution: The Missing Runtime Primitive for Agents
When an agent crashes at step forty-seven, it should resume there, not start over. Why durable execution belongs in the runtime, where framework checkpointers fall short, and how Catalyst on Dapr recovers crashed agent workflows automatically.
Jani Janakiram, MSV
Guest Author
The first post in this series named four ways production agents fail: durability, security, cost, and observability, and promised this one would start with durability. The previous post ended with a concrete promise: an agent that crashes at step forty-seven of a fifty-step job should come back at step forty-seven, not at step one. This post is about the runtime property, durable execution, that makes that happen, and why most agent frameworks do not provide this.
Durable execution is a runtime property, not a setting you toggle on. It has to solve three hard problems together, detecting that a process failed, recovering its state, and restarting it where it stopped. You cannot bolt that on after an agent is written with a try/except block or a retry decorator, because the thing that needs to survive a crash is not the code, it is the record of what the code has already done. For example, when a Kubernetes pod is evicted halfway through a business process, the memory holding that execution record goes with it. The process restarts with no idea which of its fifty steps already ran, which external systems or tools it had called, and what the tools returned. Durable execution is the runtime capability that keeps a record somewhere of the execution steps that the process does not own, so a restart becomes a resume rather than a redo.
This is the same shift enterprises made when applications moved off the developer's laptop and into production. Code that assumed a single long-lived process had to be rebuilt around the fact that processes get rescheduled, scaled, and killed. Kubernetes solved part of it. It restarts and reschedules pods when they die, but it does nothing to recover what a process was in the middle of doing, so the in-flight state inside that pod is lost. Durable execution is the missing half, the layer that brings that state back so a restarted process continues instead of starting over. Agents are a long-running, stateful, non-deterministic application type, and that combination is what forces the issue. Teams got away without durable execution when their services were stateless and deterministic. An agent that reasons across fifty steps is neither, so a lost process means lost work and lost spend, and you cannot rerun it from the top and expect the same path.
What is durable execution?
Durable execution: an execution model where every step of a workflow is persisted as it completes, so the workflow can be reconstructed and resumed from the last completed durable step after a crash, restart, or outage.
It helps to separate durable execution from two things it gets confused with. A retry just calls the same step again after a failure, which does nothing for the steps already completed before the crash. A checkpoint saves state you can reload later, but something still has to notice the process died and decide to reload it. Neither is sufficient on its own. Durable execution adds the part that is genuinely hard, detecting the failure in the first place, then recovering the persisted history and restarting the run where it stopped, with no one reconstructing what happened by hand.
The mechanism behind it is event sourcing. Instead of holding workflow state in memory and hoping the process stays alive, the runtime writes an append-only history of every step to a backing store. Dapr, the open-source CNCF runtime used in Diagrid Catalyst, calls this a replay technique. When a workflow resumes, the workflow reconstructs its state by replaying that persisted history, and completed activities return their stored results instead of running again. The web search whose result was already recorded is not repeated, and the LLM call whose response was already persisted is not billed again during replay. By the time the replay reaches the step that was interrupted, the local variables are restored and the workflow continues as if it had never stopped.
Two rules come with this model, and they are easy to confuse. The orchestration logic must be deterministic, so the same history always replays the same way. The activities must be idempotent, so that a step retried after a failure does not double its side effect. Anything that varies between runs, a timestamp, a random value, a direct network call, belongs inside an activity rather than in the orchestration, and that activity has to be safe to run more than once. The durable execution docs spell out the idempotency rules.
Durable execution recovers completed, persisted steps. It does not make non-idempotent side effects safe on its own. If an activity charges a card, posts a ledger entry, or sends an email and the process dies after the provider acted but before the runtime recorded the result, the runtime may retry that activity on recovery. Durability gives the runtime memory of what finished. Idempotency keys, transaction IDs, or an outbox pattern are what protect external systems from a duplicate side effect. You need both, and the two solve different halves of the problem.
LangGraph persistence vs runtime-owned recovery
The clearest way to see where the gap sits is in code. LangGraph is a widely used agent framework, and it ships its own persistence layer, making it a fair test of whether framework-native state-saving is sufficient.
LangGraph's persistence is real and useful. Compile a graph with a checkpointer and it saves a snapshot of graph state at every step. LangChain's own docs describe this as fault-tolerance and error recovery, letting you restart the graph from the last successful step if one or more nodes fail, with pending writes so completed nodes are not re-run. The running example through this section is a small support agent that classifies a refund ticket, retrieves the customer account, drafts the refund, then notifies the customer and closes the case. A simplified version of that graph looks like this.
from langgraph.graph import StateGraph, START, END
graph = StateGraph(State)
graph.add_node("classify", classify_node)
graph.add_node("retrieve", retrieve_node)
graph.add_node("draft", draft_node)
graph.add_edge(START, "classify")
graph.add_edge("classify", "retrieve")
graph.add_edge("retrieve", "draft")
graph.add_edge("draft", END)
compiled = graph.compile(checkpointer=checkpointer)
result = compiled.invoke(initial_state, config)What that gives you is a save point. What it does not give you, by itself, is a runtime that notices when a worker dies and acts on it. Diagrid's analysis of framework checkpointers puts the distinction directly, and it holds up. The checkpointer saves state, but there is no automatic failure detection, no automatic resumption, and no coordination to stop two workers from resuming the same thread at once. You as a developer are responsible for detecting the crash, calling resume with the correct thread ID, and handling distributed locking at scale. LangChain's managed runtime, the Agent Server, handles hosting and deployment for LangGraph, but it does not add automatic failure detection and recovery, so the orchestration burden above still sits with you.
Diagrid Catalyst's approach is a different one. You import the Diagrid Catalyst package (for many different agent frameworks) and it makes LangGraph's checkpointing run on Dapr Workflow durable execution, so failure detection, recovery, coordination, and state-store choice come from that runtime rather than from glue code you write. Without it, getting the same recovery takes a significant amount of developer work.
Diagrid Catalyst closes the gap by wrapping the same compiled graph in a Dapr workflow. You import the integration package and change the lines where you run the agent.
from diagrid.langgraph import DaprWorkflowGraphRunner
# the graph is defined and compiled exactly as before
compiled = graph.compile()
# wrap it so each node runs as a durable workflow activity
runner = DaprWorkflowGraphRunner(graph=compiled)
runner.start()The graph definition does not change, and the nodes do not change. What changes is that each node now runs as a durable workflow activity, its result persisted to a state store as it completes. The durability boundary is the runner's unit of work, a node for the graph runner and a tool call for the agent runner that wraps other SDKs. Crash the process at one of the steps and the workflow does not sit silently waiting for someone to notice. The Dapr workflow runtime detects the interruption (or failure), replays the history, skips the classify and retrieve steps because their results are already persisted, and resumes at the draft step. You as a developer write LangGraph code and get automatic recovery on failures without writing recovery logic.
Here is that recovery as an example, with each step written as an idempotent activity so it is safe to retry. The timeline makes the replay model concrete.
- Step one classifies the support ticket. The result is persisted.
- Step two retrieves the customer account. The result is persisted.
- Step three starts drafting a refund. The process crashes mid-step.
- The runtime detects the failure and restarts the workflow.
- Replay returns the stored results of steps one and two without re-running them.
- Step three reruns on the recovered worker. Because the refund write carries an idempotency key, the retry settles the same refund rather than issuing a second one, and the workflow completes.
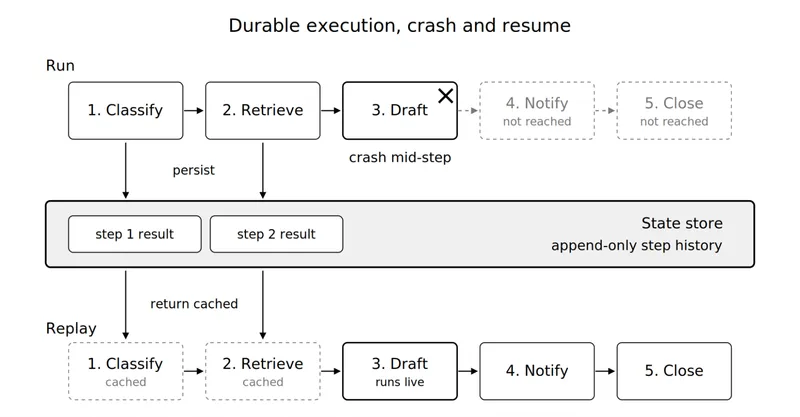 A crash at step three resumes at step three. Steps one and two return from the state store instead of running again, and execution continues to completion.
A crash at step three resumes at step three. Steps one and two return from the state store instead of running again, and execution continues to completion.
The table below sets the three options side by side. The factor that drives the choice is how much of the recovery you want to own versus how much you want the runtime to handle.
| Capability | LangGraph OSS plus a checkpointer | LangGraph managed runtime | Catalyst with Dapr |
|---|---|---|---|
| Persist execution state | Yes, once you configure a checkpointer | Yes, handled by the server | Yes, event-sourced to the state store |
| Retry a failed step within a live run | Yes, pending writes re-run only the failed node | Yes, the task queue retries the node | Yes, activity-level retry against persisted history |
| Resume after a crash | Yes, but you trigger it with the right thread ID | No, node retries are automatic but a dead worker needs the run re-triggered | Yes, the runtime detects it and resumes via durable reminders |
| Detect a dead run and restart it | No, you build detection and retry | No automatic failure detection | Yes, owned by the runtime |
| Coordinate recovery across workers | No, you handle locking and leases | No | Yes |
| Same durability model across frameworks | No, LangGraph-specific | No, LangGraph-focused | Yes, across supported frameworks |
| State store you control | Depends on your deployment and chosen saver | Postgres-oriented in LangChain's messaging | Customer-managed Dapr-supported stores |
No stack is obliged to pick one column. The point of the table is not that one option wins every row, it is that recovery, coordination, and state ownership are real decisions, and leaving them implicit is how a pilot quietly fails to become production.
Durable execution for common agent frameworks
Doing this at the runtime layer rather than inside LangGraph means the durability is not LangGraph's. The diagrid Python SDK ships the same pattern for CrewAI, Google ADK, Strands, Pydantic AI, OpenAI Agents, LangChain Deep Agents and Claude Agents. Each as a small install extra and a runner wrapper around code you already wrote. For .NET teams, the same durable execution covers the Microsoft Agent Framework in C#, a popular choice in that ecosystem, through the Catalyst .NET integration.
pip install "diagrid[langgraph]" # or [crewai], [adk], [strands], ...The Diagrid Catalyst AI agent quickstarts walk through the integration for each framework end to end.
Developers do not rewrite business logic to get this. They change the invocation boundary. Instead of invoking the graph directly, they hand the compiled graph to a runner that executes its steps as durable workflow activities. That is what makes durable execution a runtime essential rather than a framework feature. A framework defines how an agent reasons and which tools it can reach. Whether that reasoning survives a pod eviction belongs to the layer underneath, and it should not depend on which framework you picked or whether you remembered to wire up a checkpointer. For teams starting fresh, there is also Dapr Agents, an agent framework that is durable by default with no wrapper required, built to be the most compact way to ship a production agent, as the tiniest durable agent walkthrough shows.
Where the state lives
Durable execution only means something if you control where the durable record is kept, and Diagrid Catalyst keeps it in infrastructure you already operate. Workflow state persists to supported Dapr state stores, including managed options such as Postgres, Azure Blob Storage, Amazon DynamoDB, and Azure Cosmos DB. The agent's history, the thing you are trusting to bring a workflow back, sits in a database your team can inspect and back up, not in a black box inside the vendor's cloud.
This is also where the limits of the promise sit. Durable execution recovers from recoverable infrastructure failures, the evicted pods, the restarts, the brief network partitions, the provider timeout or rate-limit exception that interrupts a run. It does not fix a workflow that is deterministically wrong, since an agent that calls the incorrect tool every time will call it incorrectly on replay too. What durability removes is the failure mode where finished work is lost and not paid for twice because nothing kept the receipts, and it does that only when the activities themselves are written to be safe under retry.
Dapr, the runtime underneath this, is a graduated CNCF project already in production at companies like Grafana, NASA, and HDFC Bank, so durable execution for agents is an established mechanism pointed at a new problem.
Durable execution is necessary, and it is not sufficient. A production agent still needs a verifiable identity, authorization on every privileged call, step-level observability, and cost controls that hold at scale. Durability preserves the work and lets a crashed run finish. It does not decide whether the work was allowed, safe, or correct. Those are separate properties, and a platform that claims to make agents production-ready has to provide all of them, not just the one that keeps the receipts.
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.


