MCPゲートウェイだけでは不十分:AIエージェントにはアイデンティティ、認可、そして証明が必要
MCP ゲートウェイが解決するのはルーティングです。エージェントのアイデンティティ、認可、証明までは解決できません。自社のデータを AI エージェントに委ねるために必要なゼロトラストセキュリティを実現するには、エンタープライズ AI エージェントに何が本当に必要なのかを整理します。
以下の言語でもご利用いただけます
English · 中文 (Chinese) · Español (Spanish) · Português (Portuguese) · Français (French) · Deutsch (German) · Nederlands (Dutch) · Ελληνικά (Greek)
Mark Fussell
CEO & Co-Founder
Josh van Leeuwen
Software Engineer
MCP ゲートウェイは広く普及している(それ自体は良いこと)
Model Context Protocol(MCP)は、エージェントが外部システムにアクセスするための標準的な手段として急速に普及しました。エージェントをデータベース、SaaS プラットフォーム、コード実行環境、決済システム、社内サービスにつなぐ共通プロトコルです。エージェントが実用的な処理を行っているなら、その多くは MCP を経由しているはずです。
それに伴い、MCPゲートウェイも急速に増えています。インフラベンダー、サービスメッシュ企業、オープンソースプロジェクト、スタートアップなどが次々と MCP ゲートウェイソリューションを提供しています。これらは、MCP サーバー接続の一元的なルーティング、サービスディスカバリー、認証情報管理、基本的なアクセス制御といった実際の価値を提供します。
しかし、これらはあくまで前提条件です。セキュリティの到達点ではありません。
企業が AI エージェントをプロトタイプから本番環境へ移行し、API 呼び出し、コード実行、機密データの照会、他のエージェントとの連携を業務の一部として任せるのであれば、ルーティングとアクセス制御は必要です。ただし、それだけでは到底十分ではありません。本当に難しいセキュリティ課題は、アイデンティティ、認可、証明です。そしてMCP ゲートウェイは、このいずれも解決しません。
MCPゲートウェイが残す3つのギャップ
エンタープライズAIエージェントを本番環境に導入するには、事前に 3 つの問いに答える必要があります。MCP ゲートウェイは、そのいずれにも十分な答えを与えません。
ギャップ1:アイデンティティ。「このエージェントは誰なのか?」
MCP ゲートウェイは接続レベルで認証します。有効な API キーや OAuth トークンを伴うリクエストが届くと、ゲートウェイはそれをリストと照合し、問題なければ通過させます。これで分かるのは、認証情報が有効であることだけです。実際に誰が呼び出しているのかまでは分かりません。
実際、多くの AI エージェントはハードコードされた API キーや共有サービスアカウントのトークンで動いています。エージェント A とエージェント B が同じサービス認証情報を使って MCP サーバーにアクセスすれば、ゲートウェイからは同じ呼び出し元に見えます。エージェント自身が暗号学的に自らのアイデンティティを証明する仕組みも、下流サービスが独立して検証できる証明書ベースのアサーションもありません。
この問題は、マイクロサービスの世界では SPIFFE と mTLS によって何年も前に解決されました。各サービスは、検証可能な暗号学的アイデンティティを持ちます。サービス A がサービス B を呼び出すと、受信側のサービスは誰が呼び出しているのかを正確に把握し、それを証明できます。ところが、現在のフレームワークで書かれた AI エージェントには、この仕組みがありません。アイデンティティの空白地帯で動いており、MCP ゲートウェイはその状況を変えません。
実務上の違いは明確です。現在、多くのエージェントの呼び出しは、ツールサーバーに次のような形で届きます。
Authorization: Bearer eyJhbGciOiJSUzI1NiJ9...
つまりトークンです。複数のエージェントで共有されているかもしれません。長期間有効なままかもしれません。どのワークロードが生成したのか、どの文脈で動いていたのか、発行後にローテーションされたのかといった情報は含まれていません。ツールサーバーはそれを受け入れるか拒否するだけです。現在のアイデンティティの扱いは、それで終わりです。
SPIFFE ベースのワークロードアイデンティティでは、同じ呼び出しが証明書で裏付けられた SVID とともに届きます。これは、次のような暗号学的に署名されたアサーションです。
spiffe://diagrid.io/ns/payments/fraud-detection-agent
この URI は秘密情報ではありません。秘密である必要もありません。これはプラットフォームが発行する検証可能な主張であり、特定のトラストドメイン内の特定のネームスペースで実行されている特定のワークロードに紐づき、自動的にローテーションされ、同じトラストドメインを信頼するあらゆるサービスが検証できます。受信側のツールサーバーは、「この認証情報は許可リストにあるか」だけを確認するのではありません。どのワークロードなのか、どこで実行されているのか、この呼び出しを行うべきワークロードなのかを検証します。
前者は認証情報を保護するモデルです。後者はアイデンティティを保護するモデルです。サービス、データベース、決済システムを横断して自律的に動く AI エージェントにとって、この違いはアクセス制御とゼロトラストを分ける決定的な差になります。
標準化の観点からは、ワークロードアイデンティティに SPIFFE を用いることについて、IETFのWIMSEワーキンググループとAAIFのIdentity & Trustワーキンググループで活発な議論されています。
アイデンティティについて詳しくは、「Agent Identity: The Foundational Layer that AI Is Still Missing」をご覧ください。
ギャップ2:ルーティングを超えた認可。「このエージェントは何をしてよいのか?」
顧客データベースのMCPサーバーにアクセスできるエージェントを考えてみましょう。ゲートウェイは接続を許可し、エージェントは有効な認証情報を持ち、ルーティングルール上も許可されています。そのエージェントがワークフローの途中で、LLM が曖昧な指示を解釈し、広い条件に一致するレコードを削除する呼び出しを生成したとします。ゲートウェイはそれを止められません。ルーティングルールが定めていたのは、そのエージェントがサーバーに到達できるということだけです。到達した後に何をしてよいかは定めていません。
これが、MCPゲートウェイが残す認可のギャップです。ゲートウェイが制御するのはアクセス、つまりどの呼び出し元がどのサーバーに到達できるかです。一方で、特定のエージェントアイデンティティが、どのワークフロー文脈で、どの条件の下、どのアクションを実行してよいかという振る舞いまでは制御しません。決定論的なソフトウェアであれば、この違いは大きな問題にならないかもしれません。事前にコールグラフを推論できるからです。しかし、設計上、振る舞いが創発的で非決定論的な AI エージェントでは、これはセキュリティモデルと、セキュリティモデルに見えるだけのものとの差になります。
本番環境に必要なのは、ワークフローレベルでのデフォルト拒否型認可です。どのエージェントアイデンティティが、どのワークフローやツールを呼び出せるのかを明確に定義する宣言型ポリシーを用意し、LLM がどのような判断をしても、プラットフォーム層で強制適用できる必要があります。これらのポリシーは、スキップ、上書き、設定漏れが起こり得るアプリケーションコードの中ではなく、プラットフォームチームとセキュリティチームが管理し、バージョン管理され、監査可能なインフラ構成として置かれるべきです。
ギャップ3:証明。「このエージェントは何を行い、それを証明できるのか?」
MCPゲートウェイはログを出力します。ログは有用です。しかし、ログは証明ではありません。
企業のロギング基盤は大きく進化しました。最新の SIEM プラットフォームを使えば、ログパイプラインに改ざん耐性を持たせることができ、適切なツールを用いれば不変の監査証跡も実現できます。それでも、完全に保存されたログであっても、問いに対する答えとしては不十分です。コンプライアンスチームが「エージェントがツール呼び出しを実行する前に、人間が承認したことを示せますか」と尋ねたとき、tool: transfer_funds, status: approved, user: aliceというログエントリは答えになりません。記録されたイベントが、記録された順序で実際に発生したことを暗号学的に保証していないからです。
マルチエージェントシステムでは、この問題はさらに複雑になります。エージェント C が破壊的なツール呼び出しを行ったとき、それはエージェント B によって認可され、そのエージェント B はエージェント A によって認可され、エージェント A は人間によって起動されたものだったのでしょうか。すべてのエージェント境界を越えて伝播する署名付きの証跡チェーンがなければ、その意思決定の連鎖を再構築したり検証したりすることはできません。
署名付きチェーンのエントリは、単なるログレコードではありません。ワークフローとともに伝播する、構造化された暗号学的に検証可能なオブジェクトです。簡略化すると、次のようになります。
{
"step": "fraud_check_passed",
"agent": "spiffe://diagrid.io/ns/payments/sa/fraud-detection-agent",
"timestamp": "2025-04-18T14:23:11Z",
"result": "approved",
"signature": "eyJhbGciOiJFUzI1NiJ9..."
}各エントリは、それを生成したアイデンティティによって署名されます。チェーンが下流のツールサーバーに届くとき、そこにはワークフローを開始した人物、実行された検証ステップ、人間による承認の有無、各エントリを生成したエージェントといった完全な履歴が含まれています。ツールサーバーは処理を実行する前に、すべての署名を検証します。署名したアイデンティティが不明、署名が一致しない、必要なステップが欠けているなど、検証できないエントリがあれば、実行前に呼び出しを拒否します。
EU AI法、SECの新たなガイダンス、進化する SOC2 要件はいずれも、企業に明確な期待を示しています。AI システムに対する検証可能な制御と説明責任を示すことです。
企業に必要なのは、すべてのエージェントワークフローのすべてのステップについて、改ざん検知可能で暗号学的に署名された記録です。事後に誰かが確認するログではなく、下流サービスが動作する前にリアルタイムで検証できる証明でなければなりません。ツールサーバーは、署名付き履歴によって、人間による承認、検証ステップの通過、呼び出し元エージェントの認可が証明されない限り、破壊的なツール呼び出しを拒否できる必要があります。MCP ゲートウェイには、この概念がありません。
AI対応インフラに必要なもの
3つのギャップを埋めるには、エージェントやアプリケーションコードより下、ネットワーク/コンピュートより上に位置する AI プラットフォーム層で動作する 3 つの機能が必要です。

暗号学的なエージェントアイデンティティ
すべてのエージェントには、SPIFFE ベースの暗号学的アイデンティティ、つまりプラットフォームによって自動的に発行・ローテーションされる証明書が必要です。エージェントがツールや別のエージェントを呼び出すとき、受信側サービスは標準的な mTLS でアイデンティティを検証します。これはヘッダー内のトークンではありません。参加者がそれぞれ独立して検証できる信頼チェーンに根ざした、証明書ベースのアサーションです。マイクロサービス間通信を保護してきた実績あるアプローチを、非決定論的で自律的なエージェント特有の課題に拡張するものです。
ゼロトラストのワークフロー認可
アイデンティティだけでは意味がありません。そこに認可が必要です。プラットフォームチームとセキュリティチームには、どのエージェントアイデンティティがどのワークフローやツールを呼び出せるかを定義する、宣言型で GitOps に適したポリシーが必要です。基本姿勢はデフォルト拒否でなければなりません。明示的に許可されていないものはすべてブロックします。これらのポリシーは、プラットフォーム層で強制適用できる必要があります。
これは、「このエージェントはこのサーバーに到達できる」(ゲートウェイが行うこと)と、「この特定のエージェントアイデンティティは、この特定のターゲット上で、この特定のワークフローだけを呼び出せる。それ以外は何もできない」(本番環境で必要なこと)との違いです。
署名付き履歴に基づくPolicy-as-Code
大まかな「アイデンティティ対ワークフロー」のルールは必要ですが、それだけでは十分ではありません。認可において本当に重要になる問いは、文脈に依存します。このツール呼び出しの前に不正検知ステップは実行されたのか。過去 30 秒以内に人間が承認したのか。この呼び出しを行っているエージェントは、最初のユーザーリクエストを受け取ったエージェントと同じなのか。それともチェーンが乗っ取られているのか。
これらの問いは、リクエスト単体からは答えられません。その呼び出しに至るまでのワークフロー履歴をたどって判断する必要があります。各ステップをまたいで伝播する暗号学的に署名された実行履歴があれば、Open Policy Agent(OPA)型のポリシーエンジンで、判断の瞬間に Rego(または他のポリシー言語)をチェーン全体に対して評価できます。
allow_tool_call {
input.history[_].step == "human_approval"
input.history[_].step == "fraud_check_passed"
input.history[_].agent == input.calling_agent
}このポリシーは呼び出し元ではなく、受信側で実行されます。各エントリはそれを生成したアイデンティティによって署名されているため、エージェントは履歴を偽造できません。これにより、ワークフロー履歴そのものが、認可判断のための検証可能な入力になります。OPA が HTTP API に対して JWT クレームやリクエストコンテキストを評価するのと同じ考え方を、マルチエージェント、マルチツールの実行チェーン全体にエンドツーエンドで拡張するものです。
暗号学的な管理証跡チェーン
エージェントがサービス境界を越えて連携する場合、すべてのステップに署名が必要です。各サービスは、自身のアイデンティティ証明書で蓄積された実行履歴に署名し、改ざん検知可能なチェーンを作ります。下流のツールは、「この呼び出し元に権限があるか」だけを確認するのではありません。ワークフローを誰が開始したか、どの承認が行われたか、どの検証ステップを通過したか、チェーン内のすべてのアイデンティティが認可されているかという履歴全体を検証します。
これは、後で誰かが確認するログではありません。各ツール呼び出しの前に検証される暗号学的な証明です。これにより、ルーティングだけでは実現できない強制パターンが可能になります。たとえば、不正検知ワークフローを通過し、人間が取引を承認したことを署名付き履歴が証明しない限り、実行を拒否する決済 MCP ツールです。
実際の仕組み
これらは理論上の要件ではありません。Dapr ベースのアプリケーションと AI エージェントを本番環境で実行するためのマネージドプラットフォームである Diagrid Catalyst は、これらの機能を現在すでに提供しています。
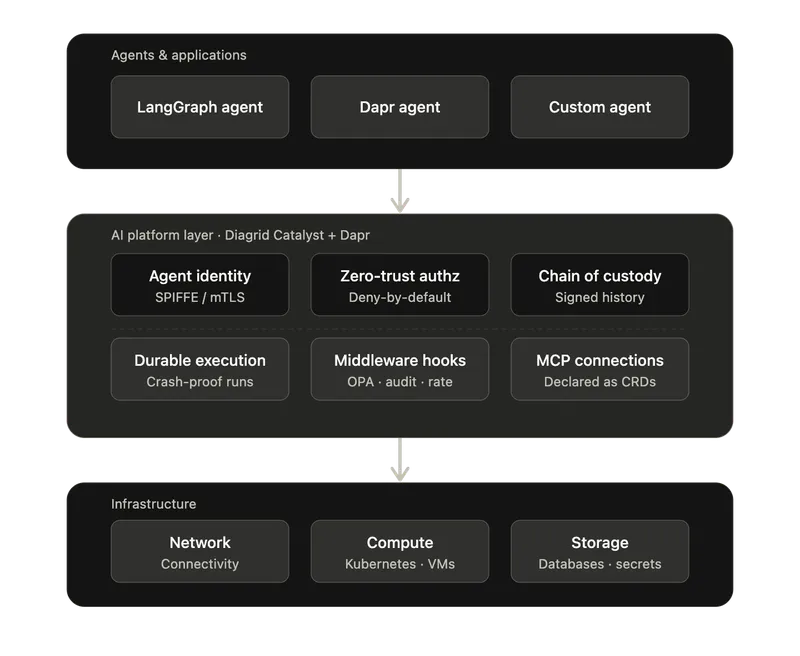
インフラとしてのMCP。MCPサーバー接続は、接続詳細、認証情報、アクセススコープを含む Kubernetes CRD として宣言されます。アプリケーションコード内に接続ロジックをハードコードする必要はありません。認証情報は実行時にシークレットストアから解決され、エージェントコードに公開されることはありません。
耐久性のあるMCPツール呼び出し。すべてのMCPツール呼び出しは、Daprサイドカー内のワークフローとして実行されます。呼び出し中にプロセスがクラッシュしても、実行は最後のチェックポイントから再開されます。長時間実行されるツール呼び出し(データベース移行、外部 API の一連の処理、コード実行)は、プロセスやノードの障害が発生しても自動的に継続します。
ミドルウェアフック。各ツール呼び出しの前後に設定可能なワークフローフックを置くことで、エージェントコードを変更せずに、ツール単位の認可、監査ログ、レート制限、入力検証、コスト管理を実行できます。これらのフック自体もワークフローであり、組み合わせ可能で、独立してデプロイできます。ツールが実際に実行される前に署名付き履歴を評価するために、OPA などのポリシーエンジンを組み込む場所にもなります。
宣言型ワークフローアクセスポリシー。ターゲットアプリケーション上で、どのアプリケーションアイデンティティが特定のワークフローやアクティビティを開始できるかを制御するKubernetes CRD です。呼び出し元の検証には SPIFFE/mTLS ベースのアイデンティティを使用します。グロブパターン、呼び出し元ごとのルール、ネームスペース全体のデフォルト拒否ポリシーをサポートします。ポリシーが存在する場合、明示的に許可されていないものはすべて拒否されます。
署名付き履歴の伝播。ワークフローは、完全な実行履歴を子ワークフローやアクティビティへ送信する設定を選択できます。ワークフローに関与するすべてのアイデンティティは、蓄積された履歴に自身のアイデンティティ証明書で署名します。下流サービスは処理前にチェーン全体を検証し、ポリシーエンジンはその履歴をもとに判断できます。
証明可能なヒューマン・イン・ザ・ループ。エージェントは、耐久性のあるワークフローイベントを通じて、人間の承認を待つために一時停止できます。下流のツールが署名付き履歴を受け取ると、承認が単にログに記録されているだけでなく、実際に行われたことを暗号学的に検証できます。
定義済みのしきい値を超える顧客返金リクエストを処理するエージェントを考えてみましょう。ワークフローは、即座に実行したり失敗させたりするのではなく、一時停止して承認イベントを発行します。
返金処理エージェントが10,000ドルのしきい値に到達
│
▼
ワークフローが一時停止 — 承認リクエストを発行
— Slackの「payments-approvals」チャンネルへメッセージを送信
— 署名付き履歴に承認待ちとして記録
— 30分間のタイムアウトを設定
│
人間が Slack 上でレビュー
│
├── 承認 → ワークフローが再開
│ 承認ステップが署名され、履歴に追加される
│
└── 却下 / タイムアウト → ワークフローが終了
却下が署名付き履歴に記録される
│
▼
返金ツールが呼び出しを受信
— 署名付き履歴に human_approval ステップが含まれていることを検証
— 承認タイムスタンプがポリシーで許可された時間内であることを確認
— 承認したアイデンティティが権限を持つ承認者であることを確認
— すべてのチェックに合格した場合のみ実行この承認は、事後に追加されたログエントリではありません。実行履歴に含まれる署名付きステップであり、ツールサーバーは処理前にそれを検証します。承認ステップが存在しない、期限切れである、または認識されないアイデンティティによって署名されている場合、ツール呼び出しは拒否されます。損害が発生した後に監査するのではありません。
企業が問うべきこと
問うべきは「MCPゲートウェイは必要か?」ではありません。おそらく必要ですし、入口側の接続管理の一部として位置づけるべきものです。MCP はプロトコルであり、MCP サーバーへの接続を大規模に管理し、ルーティングや一定のレート制限を行うインフラは必要です。
問うべきなのは、「自社の MCP インフラは、アイデンティティ、認可、証明を提供しているか」です。
AIプラットフォームは、どの認証情報が使われたかではなく、暗号学的に検証されたどのアイデンティティが呼び出しを行ったのかを正確に示せますか。各エージェントに許可される動作について、プラットフォームチームが管理し、LLM の判断にかかわらず強制されるゼロトラスト、デフォルト拒否のポリシーを適用できますか。すべてのエージェントワークフローのすべてのステップを証明する、改ざん検知可能な署名付き管理証跡チェーンを生成し、下流サービスが処理前にリアルタイムで検証できるようにできますか。
答えが「いいえ」なら、貴社にはAIエージェントのためのセキュリティレイヤーがありません。あるのはルーターです。
そして、ルーターだけでは不十分です。
Catalystについて詳しく見る。