Les passerelles MCP ne suffisent pas : les agents IA ont besoin d'identité, d'autorisation et de preuve
Les passerelles MCP résolvent les problèmes de routage. Elles ne résolvent pas les problèmes d'identité, d'autorisation ou de preuve des agents. Voici ce dont les agents IA d'entreprise ont réellement besoin pour bénéficier de la sécurité « zero trust » indispensable pour leur confier vos données en toute confiance.
Également disponible en
English · 中文 (Chinese) · Español (Spanish) · Português (Portuguese) · Deutsch (German) · 日本語 (Japanese) · Nederlands (Dutch) · Ελληνικά (Greek)
Mark Fussell
CEO & Co-Founder
Josh van Leeuwen
Software Engineer
Les passerelles MCP sont omniprésentes (et c'est une bonne chose)
Le Model Context Protocol (MCP) est rapidement devenu le moyen par défaut pour les agents d'accéder au monde extérieur : le protocole courant pour connecter un agent à des bases de données, des plateformes SaaS, des exécuteurs de code, des systèmes de paiement et des services internes. Si vos agents font quoi que ce soit d'utile, ils le font presque certainement via MCP.
Naturellement, les passerelles MCP se multiplient. Tous les fournisseurs d'infrastructure, toutes les entreprises de maillage de services, ainsi qu'un nombre croissant de projets open source et de start-ups proposent des solutions de passerelles MCP. Et elles apportent une réelle valeur ajoutée : routage centralisé, découverte de services, gestion des identifiants et contrôle d'accès de base pour les connexions aux serveurs MCP.
Ce sont les conditions minimales. Elles ne constituent pas la finalité de la sécurité.
Si votre entreprise fait passer ses agents IA du stade de prototypes à celui de la production, où ils appellent des API, exécutent du code, interrogent des données sensibles et interagissent avec d'autres agents pour le compte de votre entreprise, le routage et le contrôle d'accès sont nécessaires, mais loin d'être suffisants. Les véritables problèmes de sécurité sont l'identité, l'autorisation et la preuve. Et les passerelles MCP ne résolvent aucun d'entre eux.
Les trois failles laissées par les passerelles MCP
Les déploiements d'agents IA en entreprise doivent répondre à trois questions avant de pouvoir passer en production. Les passerelles MCP laissent ces trois questions sans réponse.
Faille n° 1 : l'identité. « Qui est cet agent ? »
Les passerelles MCP s'authentifient au niveau de la connexion. Une requête arrive avec une clé API ou un jeton OAuth valide, la passerelle la vérifie par rapport à une liste, et la requête passe. Cela vous indique que les identifiants sont valides. Cela ne vous dit pas qui appelle.
En pratique, la plupart des agents IA fonctionnent avec des clés API codées en dur ou des jetons de compte de service partagés. Lorsque l'agent A et l'agent B utilisent tous deux les mêmes identifiants de service pour accéder à un serveur MCP, la passerelle voit deux appelants identiques. Il n'existe aucun mécanisme permettant à l'agent de prouver cryptographiquement son identité, ni aucune assertion étayée par un certificat qu'un service en aval puisse vérifier de manière indépendante.
C'est un problème que le monde des microservices a résolu il y a des années avec SPIFFE et mTLS. Chaque service dispose d'une identité cryptographique vérifiable. Lorsque le service A appelle le service B, le service destinataire sait exactement qui l'appelle et peut le prouver. Les agents IA écrits avec les frameworks actuels n'ont rien de tout cela. Ils fonctionnent dans un vide identitaire, et les passerelles MCP ne font rien pour changer cela.
La différence dans la pratique est flagrante. Aujourd'hui, la plupart des appels d'agents arrivent sur un serveur d'outils sous la forme suivante :
Authorization: Bearer eyJhbGciOiJSUzI1NiJ9...
Un jeton. Potentiellement partagé entre plusieurs agents. Potentiellement de longue durée. Sans aucune information sur la charge de travail qui l'a généré, le contexte dans lequel il opérait, ou s'il a été renouvelé depuis sa dernière émission. Le serveur d'outils l'accepte ou le rejette. C'est là toute l'histoire de l'identité.
Avec l'identité de charge de travail basée sur SPIFFE, le même appel arrive avec un SVID adossé à un certificat, une assertion signée cryptographiquement qui ressemble à ceci :
spiffe://diagrid.io/ns/payments/fraud-detection-agent
Cet URI n'est pas un secret. Il n'a pas besoin de l'être. Il s'agit d'une revendication vérifiable émise par la plateforme, liée à la charge de travail spécifique s'exécutant dans un espace de noms spécifique au sein d'un domaine de confiance spécifique, renouvelée automatiquement et vérifiable par tout service faisant confiance au même domaine de confiance. Le serveur de l'outil récepteur ne se contente pas de vérifier « cette information d'identification figure-t-elle sur ma liste d'autorisation ? ». Il vérifie : de quelle charge de travail s'agit-il, où s'exécute-t-elle, et est-ce bien la charge de travail qui est censée effectuer cet appel ?
Le premier modèle sécurise l'identifiant. Le second modèle sécurise l'identité. Pour les agents IA fonctionnant de manière autonome à travers les services, les bases de données et les systèmes de paiement, cette distinction est la différence entre le contrôle d'accès et le modèle « zero trust ».
Du point de vue des normes, l'utilisation de SPIFFE pour l'identité des charges de travail fait l'objet de discussions actives au sein du groupe de travail WIMSE de l'IETF et du groupe de travail Identity & Trust de l'AAIF.
Pour approfondir le sujet de l'identité, lisez « Agent Identity: The Foundational Layer that AI Is Still Missing »
Faille n° 2 : l'autorisation au-delà du routage. « Qu'est-ce que cet agent est autorisé à faire ? »
Prenons l'exemple d'un agent ayant accès à un serveur MCP de base de données clients. La passerelle autorise la connexion, l'agent dispose d'un identifiant valide et la règle de routage le permet. L'agent est en plein flux de travail lorsque le LLM, interprétant une instruction ambiguë, construit un appel qui supprime les enregistrements correspondant à un filtre large. Rien dans la passerelle ne l'en empêche. La règle de routage stipulait que l'agent pouvait accéder au serveur. Elle ne disait rien sur ce que l'agent pouvait faire une fois sur place.
C'est là la faille d'autorisation que laissent ouverte les passerelles MCP. Elles contrôlent l'accès : quels appelants peuvent atteindre quels serveurs. Elles ne contrôlent pas le comportement : quelles actions une identité d'agent spécifique est autorisée à effectuer, dans quels contextes de workflow, sous quelles conditions. Pour les logiciels déterministes, cette distinction n'a guère d'importance ; on peut raisonner à l'avance sur le graphe d'appels. Pour les agents IA, dont le comportement est émergent et non déterministe par nature, c'est la différence entre un modèle de sécurité et l'illusion d'un tel modèle.
Ce qu'exige la production, c'est une autorisation par défaut au niveau du flux de travail : des politiques déclaratives spécifiant exactement quelles identités d'agents peuvent invoquer quels flux de travail et quels outils, appliquées au niveau de la couche de la plateforme indépendamment de ce que le LLM décide de faire. Ces politiques doivent résider dans la configuration de l'infrastructure, être gérées par les équipes de la plateforme et de la sécurité, faire l'objet d'un contrôle de version et être vérifiables. Elles ne doivent pas se trouver dans le code de l'application, où elles peuvent être ignorées, remplacées ou simplement oubliées.
Faille n° 3 : la preuve. « Qu'a fait cet agent et pouvons-nous le prouver ? »
Les passerelles MCP génèrent des journaux. Les journaux sont utiles. Les journaux ne constituent pas une preuve.
L'infrastructure de journalisation d'entreprise s'est considérablement améliorée. Les plateformes SIEM modernes peuvent rendre les pipelines de journaux inviolables, et des pistes d'audit immuables sont réalisables avec les bons outils. Mais même un journal parfaitement conservé répond à la mauvaise question. Lorsqu'une équipe de conformité demande « pouvez-vous démontrer qu'un humain a approuvé cet appel d'outil avant que l'agent ne l'exécute ? », une entrée de journal indiquant outil : transfer_funds, statut : approuvé, utilisateur : alice n'est pas une réponse. Elle n'offre aucune garantie cryptographique que les événements enregistrés se sont réellement produits dans l'ordre indiqué.
Dans les systèmes multi-agents, ce problème s'aggrave. Lorsque l'agent C invoque un appel d'outil destructeur, a-t-il été autorisé par l'agent B, qui a lui-même été autorisé par l'agent A, lequel a été déclenché par un humain ? Sans une chaîne de responsabilité signée qui se propage au-delà de chaque limite d'agent, il n'y a aucun moyen de reconstituer ou de vérifier la chaîne de décision.
Une entrée de chaîne signée n'est pas un enregistrement de journal. Il s'agit d'un objet structuré et cryptographiquement vérifiable qui suit le flux de travail. Une entrée simplifiée ressemble à ceci :
{
"step": "fraud_check_passed",
"agent": "spiffe://diagrid.io/ns/payments/sa/fraud-detection-agent",
"timestamp": "2025-04-18T14:23:11Z",
"result": "approved",
"signature": "eyJhbGciOiJFUzI1NiJ9..."
}Chaque entrée est signée par l'identité qui l'a produite. Lorsque la chaîne atteint un serveur d'outils en aval, elle contient l'historique complet : qui a lancé le workflow, quelles étapes de validation ont été exécutées, si une validation humaine a eu lieu et quel agent a produit chaque entrée. Le serveur d'outils vérifie chaque signature avant d'agir. Une entrée qui ne peut être vérifiée parce que l'identité de signature est inconnue, que la signature ne correspond pas ou que l'étape attendue est absente entraîne le refus de l'appel avant son exécution.
La loi européenne sur l'IA, les nouvelles directives de la SEC et l'évolution des exigences SOC2 convergent toutes vers une attente claire : les entreprises doivent démontrer un contrôle vérifiable et une responsabilité vis-à-vis de leurs systèmes d'IA.
Ce dont les entreprises ont besoin, c'est d'un enregistrement inviolable et signé cryptographiquement de chaque étape de chaque workflow d'agent, non pas d'un journal que quelqu'un examine a posteriori, mais d'une preuve que les services en aval vérifient en temps réel avant d'agir. Un serveur d'outils devrait être capable de refuser un appel d'outil destructeur à moins que l'historique signé ne prouve qu'un humain l'a approuvé, qu'une étape de validation a été franchie et que l'agent appelant est autorisé. Les passerelles MCP n'ont aucune notion de cela.
À quoi ressemble une infrastructure prête pour l'IA
Combler ces trois lacunes nécessite trois capacités qui opèrent au niveau de la couche de la plateforme d'IA, en dessous du code de l'agent ou de l'application et au-dessus du réseau/des ressources de calcul.

Identité cryptographique de l'agent
Chaque agent a besoin d'une identité cryptographique basée sur SPIFFE, un certificat émis et renouvelé automatiquement par la plateforme. Lorsqu'un agent appelle un outil ou un autre agent, le service destinataire vérifie l'identité via le protocole mTLS standard. Il ne s'agit pas d'un jeton dans un en-tête. C'est une assertion étayée par un certificat, ancrée dans une chaîne de confiance que tout participant peut vérifier de manière indépendante. La même approche éprouvée qui sécurise la communication entre microservices, étendue aux défis uniques posés par les agents autonomes et non déterministes.
Autorisation des workflows en mode Zero-Trust
L'identité sans autorisation n'a aucun sens. Les équipes chargées de la plateforme et de la sécurité ont besoin de politiques déclaratives, compatibles avec GitOps, qui définissent quelles identités d'agents peuvent invoquer quels workflows et outils. La posture par défaut doit être « tout refuser » : tout ce qui n'est pas explicitement autorisé est bloqué. Ces politiques doivent être applicables au niveau de la plateforme.
C'est la différence entre « cet agent peut atteindre ce serveur » (ce que font les passerelles) et « cette identité d'agent spécifique peut invoquer ce workflow spécifique sur cette cible spécifique, et rien d'autre » (ce qu'exige la production).
Politique en tant que code plutôt qu'historique signé
Des règles générales d'identité-vers-workflow sont nécessaires mais non suffisantes. Les questions d'autorisation vraiment intéressantes sont contextuelles : cet appel d'outil a-t-il été précédé d'une étape de détection de fraude ? Un humain l'a-t-il approuvé au cours des 30 dernières secondes ? L'agent qui effectue cet appel est-il le même que celui qui a reçu la requête initiale de l'utilisateur, ou la chaîne a-t-elle été détournée ?
On ne peut pas répondre à ces questions à partir de la requête seule. Elles nécessitent une analyse de l'historique du workflow qui a conduit à l'appel. Avec un historique d'exécution signé cryptographiquement et propagé à chaque étape, un moteur de politique de type Open Policy Agent (OPA) capable d'évaluer Rego (ou tout autre langage de politique) par rapport à l'ensemble de la chaîne au moment de la décision :
allow_tool_call {
input.history[_].step == "human_approval"
input.history[_].step == "fraud_check_passed"
input.history[_].agent == input.calling_agent
}La politique s'exécute chez le destinataire, et non chez l'appelant. Les agents ne peuvent pas falsifier l'historique, car chaque entrée est signée par l'identité qui l'a produite. Cela transforme l'historique du flux de travail lui-même en une entrée vérifiable pour l'autorisation, de la même manière qu'OPA évalue déjà les revendications JWT et le contexte de requête pour les API HTTP, mais désormais étendu de bout en bout à travers des chaînes d'exécution multi-agents et multi-outils.
Chaîne de conservation cryptographique
Lorsque des agents collaborent au-delà des limites des services, chaque étape doit être signée. Chaque service signe l'historique d'exécution accumulé avec son propre certificat d'identité, créant ainsi une chaîne inviolable. Un outil en aval ne se contente pas de vérifier « cet appelant a-t-il l'autorisation ? ». Il vérifie l'historique complet : qui a initié le workflow, quelles approbations ont eu lieu, quelles étapes de validation ont été franchies, et si chaque identité de la chaîne est autorisée.
Il ne s'agit pas d'un journal que quelqu'un vérifie ultérieurement. C'est une preuve cryptographique vérifiée avant chaque appel d'outil. Cela permet des modèles d'application impossibles à mettre en œuvre avec le routage seul : un outil MCP de paiement qui refuse de s'exécuter à moins que l'historique signé ne prouve qu'un workflow de détection de fraude a été validé et qu'un humain a approuvé la transaction.
Comment cela fonctionne-t-il en pratique ?
Il ne s'agit pas d'exigences théoriques. Diagrid Catalyst, la plateforme gérée permettant d'exécuter des applications basées sur Dapr et des agents IA en production, offre tout cela dès aujourd'hui.
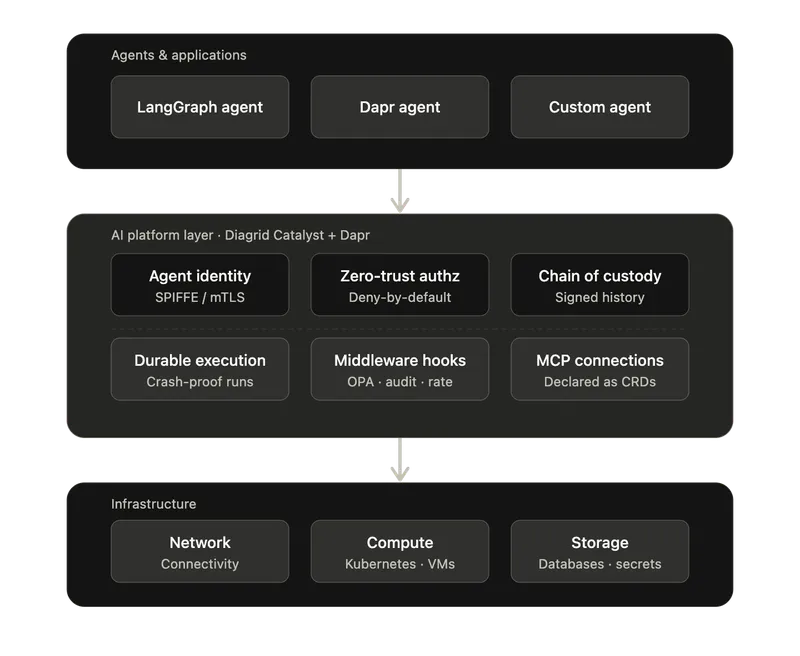
Le MCP en tant qu'infrastructure. Les connexions au serveur MCP sont déclarées sous forme de CRD Kubernetes avec les détails de connexion, les identifiants et les périmètres d'accès. Aucune logique de connexion codée en dur dans le code de l'application. Les identifiants sont récupérés à partir de magasins de secrets lors de l'exécution et ne sont jamais exposés au code de l'agent.
Appels d'outils MCP durables. Chaque appel d'outil MCP s'exécute sous forme de workflow à l'intérieur du sidecar Dapr. Si un processus plante en cours d'appel, l'exécution reprend à partir du dernier point de contrôle. Les appels d'outils de longue durée (migrations de bases de données, séquences d'API externes, exécution de code) survivent automatiquement aux pannes de processus et de nœuds.
Hooks de middleware. Avant et après chaque appel d'outil, des hooks de workflow configurables permettent l'autorisation par outil, la journalisation d'audit, la limitation de débit, la validation des entrées et le contrôle des coûts, sans modifier le code de l'agent. Il s'agit de workflows à part entière, composables et déployables indépendamment, dans lesquels vous pouvez intégrer OPA ou tout autre moteur de politiques pour évaluer l'historique signé avant l'exécution effective d'un outil.
Politique d'accès aux workflows déclarative. Un CRD Kubernetes qui contrôle quelles identités d'application peuvent lancer des workflows et des activités spécifiques sur une application cible. Utilise une identité basée sur SPIFFE/mTLS pour la vérification de l'appelant. Prend en charge les modèles globaux, les règles par appelant et les politiques de refus global à l'échelle de l'espace de noms. Lorsqu'une politique existe, tout ce qui n'est pas explicitement autorisé est refusé.
Propagation de l'historique signé. Les workflows peuvent choisir d'envoyer leur historique d'exécution complet aux workflows et activités enfants. Chaque identité intervenant dans un workflow signe l'historique accumulé avec son certificat d'identité. Les services en aval vérifient l'ensemble de la chaîne avant d'agir, et les moteurs de politiques peuvent l'analyser.
Intervention humaine avec preuve. Les agents peuvent marquer une pause pour obtenir une approbation humaine via des événements de workflow durables. Lorsqu'un outil en aval reçoit l'historique signé, il peut vérifier cryptographiquement que l'approbation a bien eu lieu, et pas seulement qu'un journal l'indique.
Prenons l'exemple d'un agent traitant une demande de remboursement client dépassant un seuil défini. Plutôt que d'exécuter immédiatement ou d'échouer, le workflow se met en pause et émet un événement d'approbation :
L'agent de remboursement atteint le seuil de 10 000 $
│
▼
Le workflow est suspendu — émet une demande d'approbation
— envoie un message Slack au canal « paiements-approbations »
— enregistrements en attente de validation dans l'historique des signatures
— définit un délai d'expiration de 30 minutes
│
Vérifications humaines dans Slack
│
├── Approuve → le workflow reprend
│ étape d'approbation signée et ajoutée à l'historique
│
└── Refus / délai d'expiration → le workflow s'arrête
le refus est consigné dans l'historique signé
│
▼
L'outil de remboursement reçoit un appel
— vérifie que l'historique signé contient l'étape human_approval
— confirme que l'horodatage de l'approbation se situe dans la fenêtre prévue par la politique
— confirme que l'identité de l'approbateur est celle d'un approbateur autorisé
— s'exécute uniquement si toutes les vérifications sont réussiesL'approbation n'est pas une entrée de journal ajoutée a posteriori. Il s'agit d'une étape signée dans l'historique d'exécution que le serveur de l'outil vérifie avant d'agir. Si l'étape d'approbation est absente, expirée ou signée par une identité non reconnue, l'appel de l'outil est refusé, et non audité une fois le mal fait.
La question que les entreprises devraient se poser
La question n'est pas « avons-nous besoin d'une passerelle MCP ? » Vous en avez probablement besoin et celles-ci devraient certainement faire partie de votre gestion des connexions entrantes. MCP est le protocole, et vous avez besoin d'une infrastructure pour gérer les connexions aux serveurs MCP à grande échelle, effectuer le routage et mettre en place une certaine limitation de débit.
La question est la suivante : votre infrastructure MCP vous fournit-elle l'identité, l'autorisation et la preuve ?
Votre plateforme d'IA peut-elle vous indiquer exactement quel agent a effectué un appel, non pas quelles informations d'identification ont été utilisées, mais quelle identité cryptographiquement vérifiée ? Peut-elle appliquer des politiques « zero-trust » et de refus par défaut sur ce que chaque agent est autorisé à faire, gérées par votre équipe de plateforme et appliquées indépendamment de ce que décide le LLM ? Peut-elle produire une chaîne de contrôle signée et inviolable qui prouve chaque étape du workflow de chaque agent, vérifiable en temps réel par les services en aval avant qu'ils n'agissent ?
Si la réponse est non, vous ne disposez pas d'une couche de sécurité pour les agents IA. Vous disposez d'un routeur.
Et les routeurs ne suffisent pas.
Découvrez Catalyst plus en détail.