Cost Optimization for LLM-Powered Agents
The standard LLM cost playbook of caching, model routing, and batch APIs optimizes single calls. Agents turn one request into many, and the real waste hides in retry storms, crash re-runs, and unattributed spend that single-call optimization can't see.
Your agent shipped two months ago. The bill came in last week. It's four times what your estimate said it would be, and nobody on the team can fully explain why. When you start digging, the picture isn't one big problem. It's five small ones stacked on top of each other.
A system prompt that's gotten longer with every revision, repeated on every call. A flaky third-party tool that quietly triggered three retries per failure, and the agent never flagged it. A planning loop that takes twenty steps to do what three steps could. A monthly invoice that shows a total but no breakdown by agent, by step, or by tool. And, last Tuesday, a crash that re-ran forty-seven completed steps from scratch because nothing persisted.
None of these show up in a per-token price estimate. Most teams discover them the way you just did: after the bill arrives. One scope note before going further. This article is about production agents, the kind that run unattended, processing work without a human reviewing each step. It's not about development agents like Claude Code or Cursor, where a human gates every turn, and the standard single-call playbook still covers most of the cost.
Here's the thing worth sorting out before you start optimizing. Some of these problems are yours to fix. Some belong to the platform underneath you. Conflating the two is how teams end up cutting the wrong things or worse, under-investing in the parts they can't fix alone.
What the standard playbook already covers
If you've spent any time on LLM cost work, you know the levers. Route simple tasks to a cheaper model. Cache the system prompt that hasn't changed in months. Cache the answer when someone asks the same question twice. Compress prompts before they hit the API. Push non-real-time work through batch endpoints for the discount.
These work. They're well-documented, they have measurable impact, and any team with a runaway LLM bill should be pulling these levers first.
There's a pattern underneath them, though. Every one of these optimizes a single call. Which model handles it? How much does that one call cost? How fast does it return? Can the input be shrunk or the output reused?
That's not a criticism. It's a description of what category of problem the playbook solves. Once you put an agent into the picture, the cost shape changes in ways that single-call optimization can't reach. Semantic caching is the cleanest example: it works beautifully for a Q&A bot, but it weakens fast inside an agent, because the agent's next call usually depends on what a tool just returned, not on the user's original question. The “same question” looks different every time it's asked.
So the standard playbook isn't wrong. It just stops covering things at a specific point. The point where one request turns into many.
What changes when one request becomes many
A chatbot is one LLM call per user turn. The cost is roughly predictable: input tokens in, output tokens out, multiply by per-token price.
Fig: A chatbot is one round-trip to the LLM.
An agent isn't shaped like that. A single user request turns into a chain that includes planning, calling a tool, reading the result, deciding what to do next, maybe calling another tool, maybe correcting an earlier mistake, maybe retrying something that failed. Five to fifty model calls per user message are normal. The total cost of an agent invocation isn't a per-call question anymore. It's an aggregate.
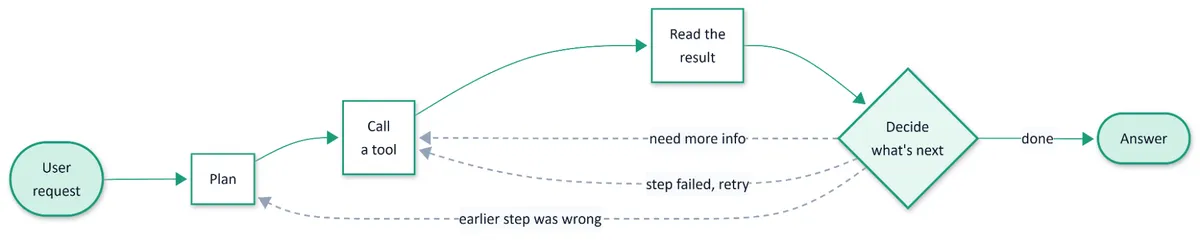
Fig: One agent turn, expanded: every dashed arrow is another LLM call the bill has to pay for.
This multiplication is where a different category of waste shows up. Three problems in particular.
- Retry storms. A downstream tool starts failing. It can happen due to slow responses, intermittent 500s, or even a timeout. Without something between the agent and the tool, the agent does what it was told to do: it tries again. The LLM is invoked to reason about the failure. It decides to retry. The tool fails again. The cycle continues. By the time someone notices, you've spent thousands of tokens reasoning about a dependency that was broken the whole time.
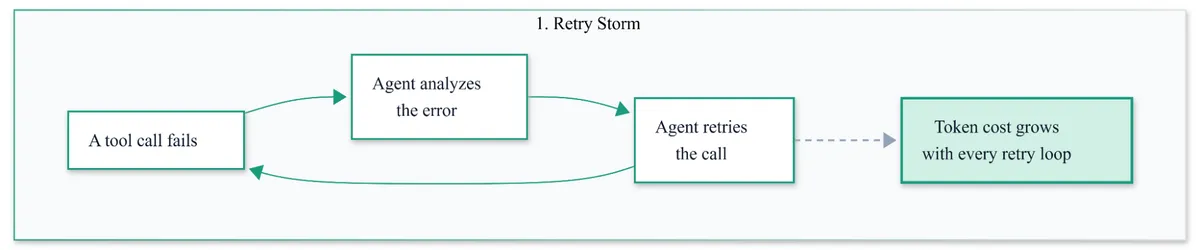
Fig: Tool call failure adds tokens, and if the failure repeats, costs spiral with every loop.
- Crash re-execution. In a system without durable execution, a long-running workflow thirty steps deep is fully exposed to any process interruption, for example, a pod eviction, a rolling deployment, or an OOM kill. Without persisted state, the execution context is lost entirely. Recovery means starting a fresh run from step one and re-incurring the full cost of every activity that has already been completed. The longer the workflow, the steeper the penalty.

Fig: A crash partway through a multi-step process wipes out progress, forcing a restart from step one.
- Invisible spend. The monthly bill shows a number. It doesn't show which agent generated it, which step inside that agent was the worst offender, which tool calls triggered cascading model calls, or which user requests turned into thirty-step loops. Optimization without this attribution is guesswork.
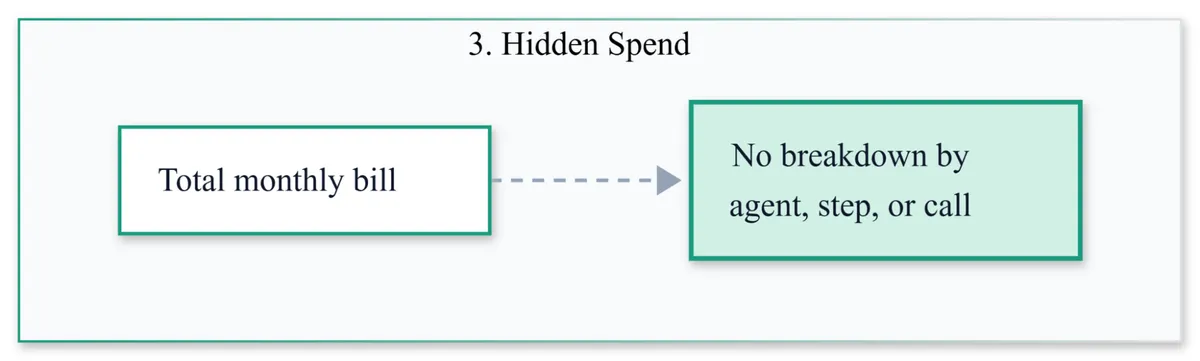
Fig: A single monthly total hides how spend breaks down by agent, step, or call.
What's not on this list is worth naming, too. How many steps your agent takes, whether your planning prompt is doing too much, whether you're calling a frontier model for a task a small model could handle, and so on. Those are agent-design choices, and they belong to the team. No platform fixes a poorly designed agent. The platform's job is the layer underneath: the parts that depend on how a multi-step workflow runs, recovers, and gets observed.
What can an agent-aware platform actually do?
This is where Diagrid Catalyst fits. Diagrid Catalyst is a reliable and secure platform for running agentic workloads in production, with the Dapr runtime, state stores, and message brokers managed for you. It doesn't replace any part of the single-call playbook. It fills the gap that opens up when a single request becomes a multi-step workflow.
Mapping it to the three problems above, in the same order.
- Declarative Resiliency Primitives. Timeouts, retries with exponential backoff, and circuit breakers are configured once at the platform layer instead of hand-rolled inside every agent. When a dependency starts failing, the circuit breaker trips and opens, and the agent stops hammering it. Calls fail fast instead of triggering more reasoning. This is primarily a reliability feature; the cost benefit is a side effect, not a marketing line. But the side effect is meaningful: a cascading failure stops cascading into your token budget.
- Durable Execution. The workflow's state is persisted at each step, so a crash mid-run resumes from the last completed step instead of restarting from scratch.
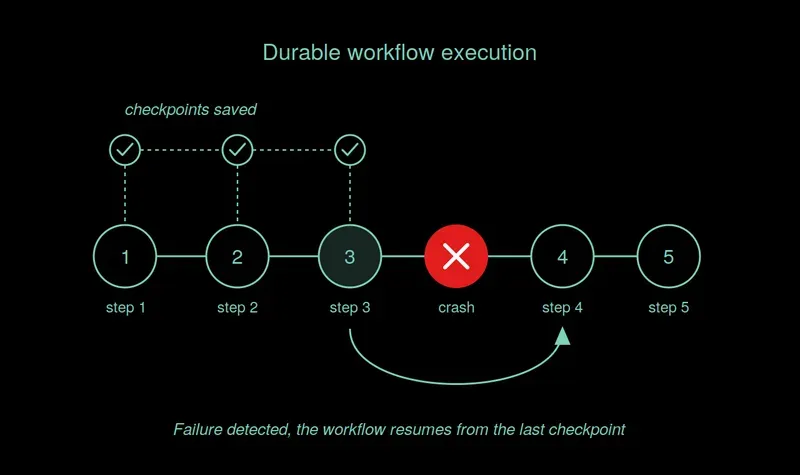
Fig: Durable execution resumes from the last checkpoint, not from the beginning.
Completed steps aren't re-run; rather, their results are replayed from history. This way, the token cost of work that already succeeded is paid once, not twice. We covered the mechanism itself in the durable execution article in this series; the cost angle here is the practical follow-on.
- Invisible spend. Every workflow run is captured with per-step detail: which agent ran, what steps it took, which tool calls happened inside each step, how long each one took, and what it consumed. Cost attribution stops being a back-of-the-envelope exercise and becomes something you can actually look at by agent, by step, by tool call. The bill stops being a single number you can't explain.
The boundary is worth restating. Diagrid Catalyst fills a specific, narrow gap. It does not replace prompt caching, model routing, semantic caching, or batch APIs. It addresses the cost problems that come from how a multi-step workflow runs and fails. The ones that single-call optimization can't see.
Where to go next
The point isn't that agent cost optimization replaces general LLM cost optimization. They're different problems, and conflating them leaves real savings on the table either way. The standard playbook is the right starting point. Once you're past it, the next layer of waste lives in the workflow shape itself, and you need different tools to see it.
There's a natural next question, too. Once a single agent's cost profile is under control, what happens when many agents need to run together in production? These agents are coordinating, sharing state, and handing off work? That's a different set of problems again, and we'll cover it in the next article in this series.
If you want to go deeper on the foundations underneath all of this, durable agents, workflows, and the patterns that show up once you run them in production, the Dapr Agents track on Dapr University is the place to start.
Frequently asked questions
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.