Securing AI Agents: Implementing Agent Identity
Static API keys aren't identity. They're copyable passwords with no scope. SPIFFE and mTLS give agents a cryptographic identity the platform can verify, scope, and revoke.
Walk into the agent codebase of almost any team shipping AI right now, and you'll see the same pattern. An agent fires off a tool call. That call invokes another agent, which queries a database, which hits an external API. Three hops deep, and every link in the chain is authenticated the same way. A static credential such as a key in an environment variable, a secret in a config file, a bearer token that should have been rotated last quarter.
It works. Until it doesn't.
The problem isn't that the keys are weak. The problem is that none of this is actually identity. It's credentials, and credentials can be copied. Any process that gets hold of the key becomes the agent, and there's no way to tell the difference from the outside. The receiving service can't distinguish between the agent it was built to trust and a script that happens to have the same string in memory.
This is not a new problem. Microservices faced it twenty years ago, and the industry spent the better part of a decade solving it. Agents make the challenge more acute. They do not simply call services when instructed. They decide what to call, in what order, and with what arguments. A compromised credential in an agent does not expose a single endpoint. It exposes everything the agent can access.
The question is what it would take to give an agent an identity that the platform can verify on every call, limit to specific resources, and revoke immediately when something goes wrong.
The credential problem agents haven't solved
Most agents authenticate the way early microservices did. A key gets minted somewhere (cloud console, a secrets manager, sometimes just a developer's terminal), dropped into an environment variable, and the agent presents it to every service it calls. If there's a rotation policy, the key is replaced quarterly. Often there isn't one.
The core problem is a matter of category. These credentials function as passwords rather than identities. The difference matters more than it sounds. An identity is inherent to the workload. It's a property of the running process that can be cryptographically verified by anyone who needs to. A password is simply something the workload possesses. Anyone holding the same string can present it and be trusted. Once copies proliferate, the security model weakens.
Now layer in what makes agents different from a traditional service. A microservice has a known, finite set of endpoints it calls. An agent reasons about what to do next and assembles tool calls dynamically. One agent run might touch a database, a vector store, an external API, and three internal services. The code may not have referenced any of them ahead of time. If its credentials are compromised, you don't just lose a single integration. You lose whatever the agent could reach. The model determines the agent's reach dynamically. As a result, the attack surface is larger and less predictable than any single integration.
A real identity works differently. It belongs to the running workload, not a deployment artifact or a secret passed in at startup. Every connection can be verified cryptographically. Access can be limited to specific resources through policy. And when something goes wrong, that identity can be revoked immediately instead of waiting for the next key rotation.
What workload identity actually means
The shift is simple. The identity belongs to the workload itself, the running process. It does not belong to the developer who deployed it, the cloud account it runs in, or the secret injected at startup. That distinction is the core of the model.
This is the approach that solved a similar problem for microservices, formalized in SPIFFE. SPIFFE, the Secure Production Identity Framework for Everyone, is an open standard and a graduated project under the Cloud Native Computing Foundation. It defines how to give workloads cryptographically verifiable identities that are independent of the underlying infrastructure.
The unit of identity is a SPIFFE ID that uniquely identifies a specific workload within a trust domain. For example:
spiffe://prod.example.com/agents/billing-agentThe SPIFFE ID is stable. It doesn't change when the agent restarts, moves between hosts, or scales out to ten replicas. It's portable. The same identity works whether the workload runs on Kubernetes, a VM, or a developer laptop. And it's tied to a cryptographic credential. It's an X.509 certificate or a JWT, formally called an SVID, that the workload uses to prove the ID is genuinely its own.
The lesson from microservices applies directly here. Identity needs to be issued and verified at the infrastructure layer, not asserted by the application. By the time the application is the thing answering “who are you?”, the question has already been answered wrong.
How identity gets verified on every call
Knowing the agent has an identity is one thing. Verifying it on every call is another.
Standard TLS is asymmetric. The server proves it is who it says it is, the client trusts that proof, and then data flows. Good enough for a browser hitting a public website. Not enough for an agent in production, because nothing on the wire actually identifies the caller.
mTLS (Mutual TLS) closes that gap. Both sides present certificates. Both sides verify the other's certificate against a known authority before any data moves. The receiving service doesn't have to trust an API key in a header. It can read the calling workload's SPIFFE ID directly from the certificate it just verified. That's cryptographic proof of which workload is on the other end of the call, not an assertion the caller made about itself.
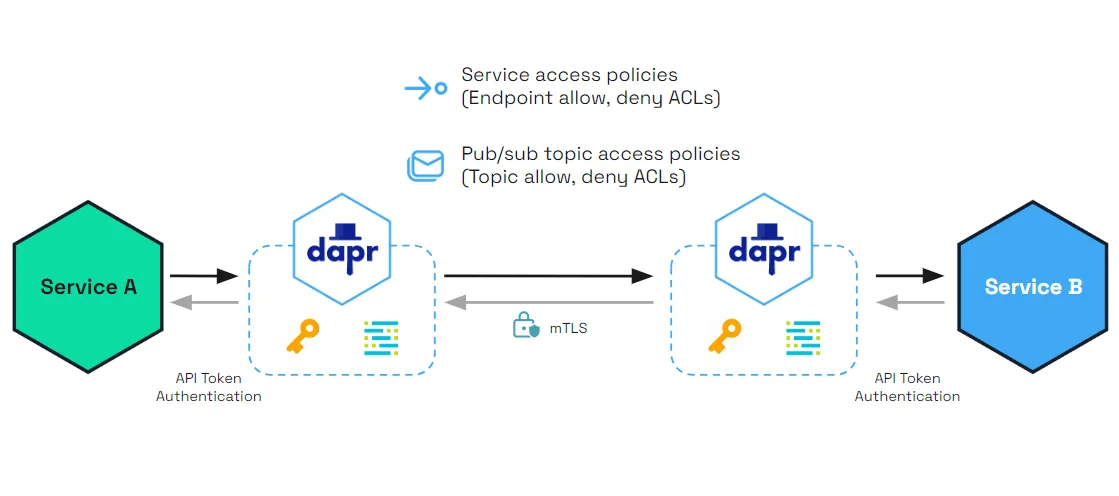
Fig: Dapr provides end-to-end security with the service invocation API
Because the certificates are short-lived. They are typically rotated every few minutes to a few hours. There's no long-lived secret to steal. A leaked certificate is useful for the rest of its TTL, and then it's gone. No credentials are sitting in a config file long past their useful life, waiting to be discovered by someone with read access to a repo.
This comes with real operational overhead. Certificate issuance, distribution, rotation, and revocation all need to be handled correctly, and at scale that becomes a platform problem rather than an application concern. Most teams do not implement this directly in the application layer. In systems like Dapr, which Diagrid Catalyst is built on, this is handled by a dedicated service called Sentry.
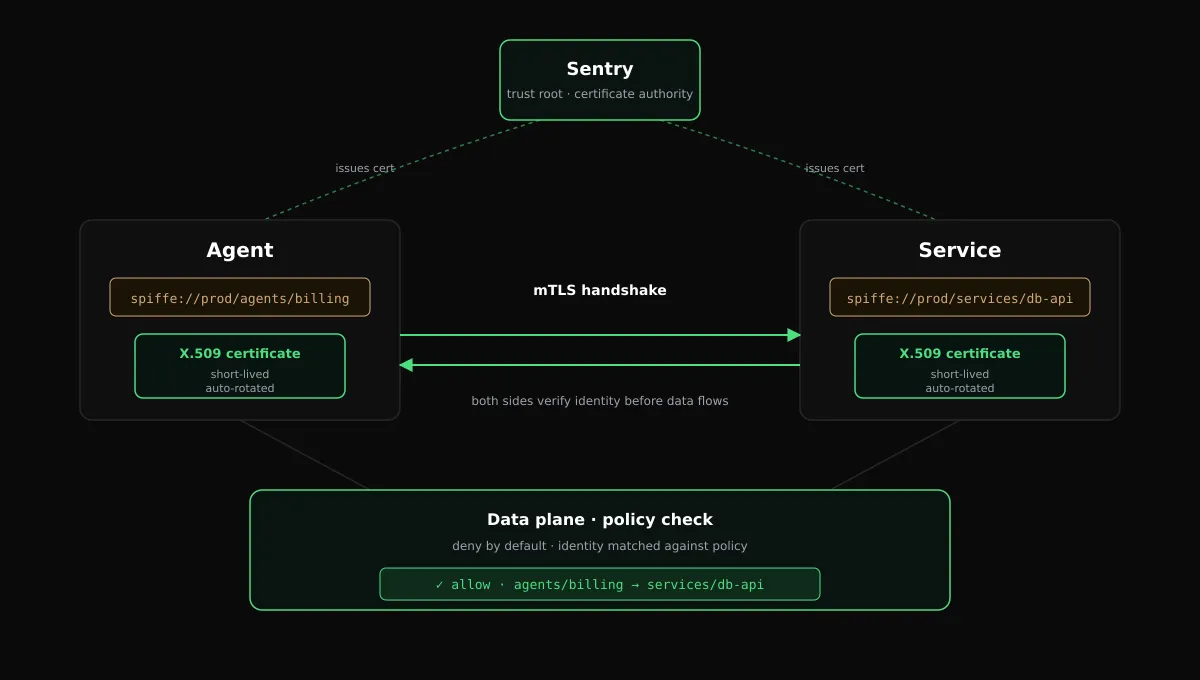
Fig: How an agent's call gets identified, verified, and authorized
Sentry issues certificates, rotates them automatically, and enforces the trust model the platform engineer defines once. No certificate logic ever lands in application code.
Identity without authorization is half the job
Identity answers “who is calling.” Authorization answers “and what are they allowed to do?” The two are easy to conflate, and conflating them is how things go wrong.
An agent with a verified SPIFFE ID is still just an authenticated workload. Verified identity doesn't say anything about what that workload should be allowed to reach. The state store, the message broker, the other services on the network by default, identity alone unlocks none of it. That's a feature, not a gap.
The right model is scoped access. An agent's identity gets bound to specific resources through explicit policy. Component scoping handles the infrastructure side. This agent can read from these state stores, publish to these broker topics, and nothing else. Access control policies handle service-to-service calls. This agent can invoke these methods on these services, and no others. Everything outside the explicit permission set is unreachable.
The default posture matters as much as the policies themselves. Deny-all by default means nothing is reachable until someone says it is. This sounds restrictive, but it's the only model that scales as the number of agents grows.
Allow-by-default systems require you to anticipate every permission you'd ever want to revoke. Deny-by-default systems require you to think clearly about what each agent actually needs. Only one of those is realistic in an environment where agents are being added weekly, and the blast radius of any single one is unknowable in advance.
This is what separates a security layer from a router. A router checks whether the credential is valid and forwards the call. A security layer checks whether this specific identity is allowed to make this specific call, against a policy defined at the platform level, not asserted by the application that wrote the call. The difference shows up the first time an agent does something it wasn't supposed to. With a router, you find out in the logs after the fact. With a security layer, the call never happens.
What this looks like in Diagrid Catalyst
Diagrid Catalyst is a reliable and secure platform for running agentic workloads in production, with the Dapr runtime, state stores, and message brokers managed for you. The identity primitives described above ship out of the box, not as a hardening checklist to work through before going live.
Every agent running on Diagrid Catalyst is assigned a SPIFFE-based cryptographic identity automatically. There's no setup step where the developer mints a credential or registers a workload by hand. The identity comes with the runtime. Certificates are issued and rotated by the platform on a schedule the developer never sees. mTLS between agents and services is enforced by default, not opt-in.
Access policies are defined at the platform level, in YAML, by the team that owns the trust model. Developers writing agent code don't write auth logic. They call tools and services, and the platform decides whether each call is permitted based on the policies the platform team has set. The application stops being the thing in charge of security decisions, which is exactly where it stopped being trustworthy in the first place.
Diagrid Catalyst also integrates with the identity providers organizations already use such as Azure Entra ID, Okta, AWS IAM Identity Center, and Google Cloud Identity. Agents fit into the existing enterprise trust model instead of introducing a parallel one. This matters in practice because security teams do not need to learn a new identity system, compliance teams do not need to audit a new trust root, and the organization does not end up with two answers to the question of who a workload is and what it can do.
Where to go next
Identity is the foundation, not something added before a compliance review. Without it, there's nothing to scope, nothing to audit, nothing to revoke. Every later layer of agent security, including policy enforcement, audit trails, and blast-radius containment, assumes that identity is already solved underneath it.
Once that foundation is in place, the next question becomes structural. With every agent carrying a verifiable identity, how do you actually govern what hundreds of them are allowed to do? How do you write access policies that scale across teams and environments without becoming a YAML graveyard? How do you keep an audit trail that compliance can actually use, and your incident responders can actually read? That's the territory of agent governance at scale, and it's where the next article picks up.
The Security & Enterprise Readiness track at Dapr University picks up where this piece leaves off. It covers zero-trust agent communication, PII handling, and the compliance work needed to move agents into production.