Architecting a Production-Ready AI Agent
Production environments are unpredictable. Workflows restart, state is lost, and tool calls fail unexpectedly. This piece explores how to architect production-ready AI agents that can survive failures.
AI agents look good in demos. You ask your agent to process a batch of invoices. It reasons through the first few steps, updates a database, and then a network timeout occurs. The service restarts.
In a demo, this usually goes unnoticed. You refresh the app, rerun the workflow, and move on.
In production, the same failure is far more serious. The agent loses its state. Its memory is lost, leaving the task half-finished and the system in an inconsistent state.
This is the reality of deploying agents into production environments. Systems that look impressive under controlled conditions often expose fragile workflows when faced with retries, crashes, partial failures, and distributed execution.
By the end of this piece, you will understand what it actually takes to architect a production-ready AI agent that can work reliably in real-world systems.
Why agents fall apart outside demos
A demo is a controlled environment. It is a “happy path” where the network is stable, the agent follows the script, and the process completes within seconds. A production environment is the opposite. It is distributed, asynchronous, and often unpredictable, where failures can happen.
When you move an agent from a prototype to a production pipeline, several reliability issues appear that a basic LLM wrapper cannot solve:
Agents lose continuity
The most common failure in production is the “amnesiac agent.” In a demo, an agent runs as a single process. If that process crashes or the container restarts, you simply rerun it.
In production environments, agents frequently handle long-running tasks like processing complex insurance claims or managing a multi-day procurement workflow that far exceed the lifespan of a single network request.
- No state persistence. Without a method to preserve the execution state, a crash causes the agent to lose its place. It cannot determine which tools it has already called or what the results were.
- Context window limits. Even though LLMs today support much larger context windows than earlier models, context windows remain a volatile and expensive form of memory. Relying on them for long-term continuity results in context bloat, causing the agent to become slow, expensive, and prone to losing focus.
Identity is unknown
In a demo, we implicitly trust the agent because we are the ones running it. However, in a production environment, an agent requires an identity that serves as the basis for authorization, auditing, and secure tool execution.
- The trust problem. Without a cryptographic identity, downstream services cannot verify whether a tool call was initiated by a legitimate agent or a malicious actor. This makes systems vulnerable to agent-in-the-middle (AiTM) attacks, where an adversary intercepts and alters messages. Identity enables the use of mechanisms like digital signatures and hash verification to ensure instructions were sent by the authorized source and have not been altered in transit.
- Auditability. If an agent updates a database or sends an email, the system logs must clearly indicate which specific agent instance performed the action. Without a distinct, first-class identity, it becomes impossible to audit, authorize, and trace actions back to their origin.
Tool calls are risky
In demos, tool calls are often direct API requests with no real consequences. In production environments, tool calls can have side effects.
- The partial failure problem. If an agent calls a “Send Payment” tool and the network times out before receiving a confirmation, what should the agent do? If it retries, it might send the payment twice. Without idempotency and transactional consistency, partial failures can leave your business data in an inconsistent and risky state.
- Orchestration chaos. Orchestration requires control over tool calls, retries, rollbacks, and error recovery. Without this control layer, even simple failures can lead to duplicated actions, inconsistent states, or broken execution flows. Standard agent frameworks often delegate this coordination to the LLM. When this control is left entirely to the LLM, execution becomes less predictable, as LLM's behavior can vary between runs, resulting in inconsistent execution behavior.
Hard to monitor and scale
Demos are designed to succeed and are typically run in controlled conditions. Production systems must be designed to be understandable when they fail under real-world loads. This requires a clear understanding of what occurred during agent execution and maintaining predictable behavior as the system scales.
- The black box problem. Standard logging is not enough for agents in production because understanding failures requires more than just error messages and request logs. You need to see the reasoning chain, tool outputs, and state transitions altogether.
- Distributed load. As deployments scale to thousands of concurrent agents, their non-deterministic nature makes behavior hard to predict. A single agent can spawn multiple sub-agents, each capable of repeatedly calling the same tool in a loop or triggering runaway executions. This turns one upstream request into an unpredictable fan-out of downstream load.
Requirements of production agents
Building a production-ready AI agent requires more than an LLM generating responses and calling tools. It requires capabilities that manage failures, preserve execution state, coordinate workflows, and provide operational visibility.
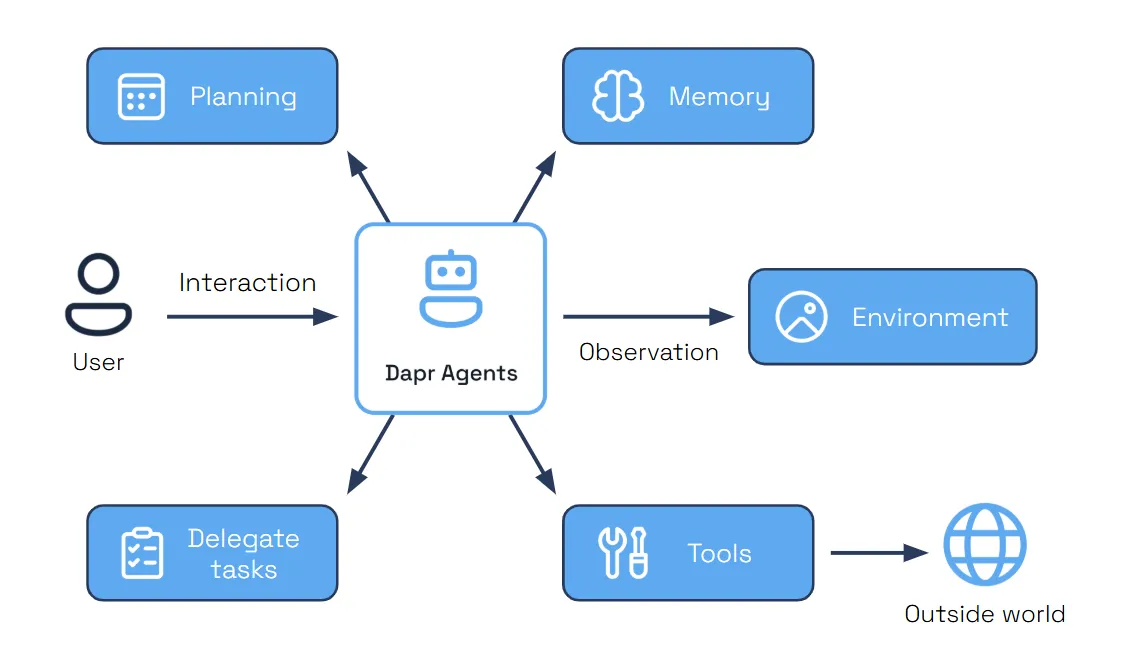
Below are the core requirements that form the foundation of reliable agent systems operating in production environments.
Durable workflows
Production-ready AI agents use durable workflows. These workflows act as an orchestration layer that persists the agent's state externally after each step. This ensures the execution history is preserved in a way that survives infrastructure failures.
The system creates resumption semantics, which is the ability to remember every agentic step. And when a crash happens, the agent picks up from that specific point after a crash. This does not leave tasks unfinished.
Durable workflows also incorporate essential resilience patterns:
- Saga patterns. These manage multi-step actions, ensuring that if one step fails, the system can coordinate compensating transactions to undo previous steps and maintain data integrity.
- Circuit breakers and retries. These mechanisms allow the system to differentiate between a transient glitch, like a two-second timeout, and a permanent failure, like an invalid API key.
This distinction is vital for operational stability. It prevents the agent from getting stuck in infinite retry loops and helps isolate failures within the workflow.
Memory and state
Production-ready AI agents require session memory that preserves the details of a user's request, prior reasoning, and intermediate outcomes across both time and devices. This allows for continuity. A user can step away from a long-running task and return days later without the agent losing its place or forgetting established context.
For this continuity to be reliable, an agent's state must be externalized. It should not depend on volatile or in-memory execution tied to a single server. The agent's workflow progress must be stored in an external state store. This decouples the agent's logic from the underlying infrastructure.
Agent identity
In distributed production environments, the identity of an agent is a critical security and auditing concern. Agent identity involves assigning a unique, cryptographically verifiable identifier to each agent instance.
Standards such as JSON Web Token (JWT) and Mutual Transport Layer Security (mTLS) allow downstream services to independently verify the origin of a request. This foundation enables a Zero Trust model, where an agent's access to specific tools or sensitive data is strictly authorized and recorded. Every prompt, decision, and tool parameter is linked to an immutable identity, providing tamper-proof audit logs essential for regulated industries such as finance and healthcare.
Structured tools
For an agent to interact safely with external systems, its tools must be structured to use function calling with clearly defined parameters. These are typically expressed through schemas such as JSON Schema or OpenAPI, which strictly define the inputs the tool accepts and the outputs it returns.
This layer also manages how tools are executed, including rate limiting, quota enforcement, retries, and parallel execution. These features enable agents to coordinate complex sequences of actions across external systems while ensuring reliable and controlled execution.
Observability
In production systems, a single user request can involve multiple LLM calls, tool executions, retries, and state updates across various services. When something breaks, you need a way to reconstruct the entire execution, not just the final error.
Agent observability addresses this by relying on distributed tracing. It records every step of execution as a connected timeline, including the initial prompt, intermediate model outputs, tool calls, tool responses, and state transitions.
The result is a comprehensive execution trace that shows how a decision unfolded over time. With this level of visibility, developers can replay a failed execution, identify where a tool call failed, where latency spiked, or where the agent's reasoning diverged from the expected path.
Pub/Sub coordination
In production distributed systems, forcing every action to be synchronous creates a distributed monolith that is difficult to scale. Pub/sub coordination decouples agents through event-driven messaging.
Instead of calling each other directly, agents publish structured event messages like “task-completed” to a topic. Other agents subscribe to these events and react when they arrive. Pub/Sub serves as the intermediary that routes messages between agents asynchronously. This enables systems where work can continue even if some components are temporarily unavailable.
Evaluation
At scale, single-pass LLM outputs are insufficient for ensuring reliable agent behavior, as they may generate hallucinations, misuse tools, or exhibit inconsistent reasoning. Evaluation is therefore a critical requirement in production.
It verifies that agent actions achieve the intended outcomes, that tool calls are valid and correctly executed, and that reasoning remains consistent across executions. This process can include evaluate-and-refine loops, where one model generates outputs and another critiques and improves them before final execution in real-world systems.
Infrastructure flexibility
AI systems evolve quickly, and the underlying models, cloud services, and tools change at the same pace. Infrastructure flexibility requires designing agents that are not tightly coupled to a single model provider or platform.
Instead of depending on specific storage, messaging, or model services, agents can interact with underlying components through consistent APIs. This keeps the agent's core logic independent from infrastructure concerns. It allows services to be swapped or upgraded without redesigning the agent.
This flexibility also enables cost optimization through intelligent model routing and resource allocation. Lightweight models can handle simpler tasks such as classification or extraction, while larger models can be reserved for complex reasoning and planning tasks. This ensures efficient resource usage while maintaining performance and reliability.
Over time, this approach enables adoption of new models and providers without changes to the core agent architecture.
How to build a production-ready AI agent with Diagrid and Dapr
Building production-ready AI agents does not have to involve manually assembling a fragmented stack of individual features.
Instead, you can use a runtime that already handles distributed systems concerns.
Diagrid provides runtime primitives that support state management, workflows, messaging, and observability. These capabilities apply regardless of the underlying agent framework.
These primitives correspond to the core requirements of production-ready AI agent systems:
- Durable execution. Use durable workflows that provide a stateful execution model where each step of an agent is defined as an activity within the workflow. These activities can call services, interact with state stores, or trigger pub/sub events, while the workflow engine automatically persists progress after each step.
- External state. Store workflow progress, session context, and intermediate results outside the running process in an external state store. This allows agents to recover their last known state after restarts, failures, or scaling events, and continue execution from where they left off.
- Event-driven coordination. Pub/sub enables agents to communicate through events instead of direct calls. Messages are routed through a broker, keeping services independent of the underlying messaging system. This pattern enables asynchronous workflows and improves scalability in distributed systems.
- Structured tool execution. Define tools with clear input and output schemas and enforce function calling. This makes tool usage more predictable, reduces ambiguity during execution, and enables validation and safer retries. It also supports building idempotent and reliable workflows in production systems.
- Observability. Diagrid Catalyst provides end-to-end visibility across agent frameworks by automatically capturing traces, logs, and metrics. You can follow execution paths across services, understand latency and failures, and debug issues at the workflow level instead of isolated errors.
Building a durable agent
A production-ready AI agent requires a runtime environment that integrates workflows, state management, and recovery as essential components of execution.
With Diagrid Catalyst, the agent runs within a durable workflow. The workflow persists its state after each step, ensuring that execution progress is not tied to a single process or container instance. If a failure occurs, the workflow resumes from the last completed step rather than starting over.
State management follows the same pattern. External state stores persist agent memory and workflow context across restarts, scaling events, and long-running tasks. This enables agents to maintain context during extended executions while preserving continuity.
Every tool the agent can invoke has a clearly defined input and output structure. This makes execution more predictable, easier to validate, and safer to retry in case of failures. Without this structure, recovery is guesswork. The system cannot reliably determine which inputs were provided, which actions completed, or what still needs to run.
As systems scale, coordination between services and agents is just as important as execution. Pub/sub messaging can replace many direct service calls. It enables agents and services to communicate through events rather than relying on tight coupling between components.
Observability focuses on making execution transparent and debuggable. Each agent run is recorded as an execution trace that includes tool calls, model outputs, and workflow checkpoints. When a failure occurs, you do not simply inspect isolated logs. Instead, you reconstruct the entire execution path the agent followed through the system.
Where to go next
This piece has laid out the architectural blueprint for moving beyond fragile prototypes to develop production-ready AI agents. We have explored how Diagrid and Dapr provide the building blocks to ensure durability, state, and identity required to make agents reliable in production environments.
However, a blueprint is only the starting point. You need to explore in more depth how agents manage their internal states and coordinate with the broader system.
The next stages of this series will take you through:
- Stateful vs. Stateless Agents: We explore why state is the anchor of reliability.
- Durable Agents: We will look at how systems survive crashes and manage tasks that span days or weeks.
If you are ready to start building, explore the resources below: