AI 101: Generative AI, Agents, and LLMs
Three terms get used as if they meant the same thing: generative AI, large language models, and agents. They don't. Here's how to tell them apart — and why it matters.
If you've read anything about AI in the past two years, you've probably seen three terms used as if they meant the same thing: generative AI, large language models, and agents. They don't. They describe three different layers of the same stack, and mixing them up leads to a lot of confused conversations, inflated expectations, and the occasional expensive mistake.
So let's sort them out. By the end of this piece, you should be able to define each one clearly, explain how they relate to each other, and spot why the difference actually matters.
Generative AI: the broadest term
Start at the top. Generative AI is the biggest umbrella of the three. It covers any AI system whose main job is to create something new, rather than classify, score, or predict things about data that already exists.
That distinction is worth slowing down on. For most of the history of applied machine learning, AI systems were built to answer questions about things you showed them. Is this email spam? How likely is this customer to cancel? Which products should we recommend? Those are discriminative tasks. The system looks at an input and puts it in a bucket.
Generative systems do something different. They produce something that wasn't there before. A paragraph of text. A photograph of a person who doesn't exist. A short tune. A block of code. A protein structure. The model has learned enough about the patterns in its training data to make new examples that plausibly belong to the same world.
This is why generative AI is a category, not a specific technology. It includes:
- Large language models, which generate text.
- Diffusion models and generative adversarial networks (GANs), which generate images, video, and audio.
- Code generation systems, which are really just specialized text generation.
- Scientific models that generate protein structures, molecules, or materials.
What ties them together is what comes out the other end: they create. What sets them apart is how they're built and what they're trained on.
It's also worth knowing what generative AI isn't. A search engine isn't generative on its own, even if it now uses generative AI to summarize results. A recommendation engine isn't either. It picks from things that already exist. A fraud-detection model isn't generative. A lot of the AI running quietly in production today is still discriminative, and that isn't going away.
Large language models: the engine behind most generative text
Within generative AI, the subcategory that gets the most attention right now is the large language model, or LLM. When most people say “AI” today, they usually mean an LLM, whether they know it or not.
At the most basic level, an LLM is a statistical model trained to predict the next token in a piece of text. A token is a small chunk of text: usually a word, part of a word, or a punctuation mark. Given the tokens that came before, the model assigns probabilities to every possible next token and picks one. Repeat that a few thousand times, and you get coherent paragraphs.
That description is accurate but also a little misleading. It's a bit like describing a movie as “a series of still pictures shown quickly.” True, but it leaves out why the thing is interesting. What makes LLMs remarkable is that this simple objective, scaled up to hundreds of billions of parameters (the internal dials the model learns during training) and fed a huge chunk of everything humans have ever written down, produces a system that can seem to reason, explain, write in different styles, translate, and hold a conversation.
A few properties of LLMs are worth knowing, even if you never plan to build one.
Context window. An LLM can only pay attention to so much text at once. That limit is called the context window. Everything the model “knows” about your specific problem has to fit inside it: your instructions, the conversation so far, any documents you want it to consider, and the response it's working on. Context windows have grown a lot in a short time, from a few thousand tokens in early models to millions in current ones, but they're still finite, and filling them up has real costs in both speed and money.
Training cutoff. An LLM's knowledge of the world stops at whatever date its training data stops. If the model was trained on data through, say, last April, it doesn't know anything about what happened in May. This is why LLMs can't reliably answer questions about current events unless you feed them fresh information at the moment you ask.
Non-determinism. Ask an LLM the same question twice and you'll often get two different answers. This is partly because the model samples from a probability distribution, and partly because of how modern hardware runs these computations in parallel. If you need reproducible outputs, you have to plan for this.
Hallucination. LLMs will, with total confidence and perfect grammar, tell you things that aren't true. This isn't really a bug. The model was trained to produce text that looks like its training data, not text that is true. Truth and plausibility overlap a lot when the training data is good, but they're not the same thing, and they come apart in exactly the situations where it matters most.
The LLM landscape splits roughly into closed models, built and operated by particular companies and used through APIs (application programming interfaces, the standard way software talks to other software over the internet), and open models, where the company releases the model itself for anyone to download and run. That download is a giant file of numbers, called the model's weights, which are basically the memory of everything the model learned during training. With the weights, you can run the model yourself, assuming you have the hardware for it. The closed group includes most of the frontier models you've heard about, meaning the most capable systems available at any given moment. The open group has come a long way and now includes models that get close to the frontier, if you've got the infrastructure to run them.
Agents: what happens when a model gets tools and a goal
An LLM on its own is a text machine. Text goes in, text comes out. By itself, it can't look something up, send an email, run a calculation, query your database, or do anything out in the world. That's a real limitation, because the world isn't made of text alone.
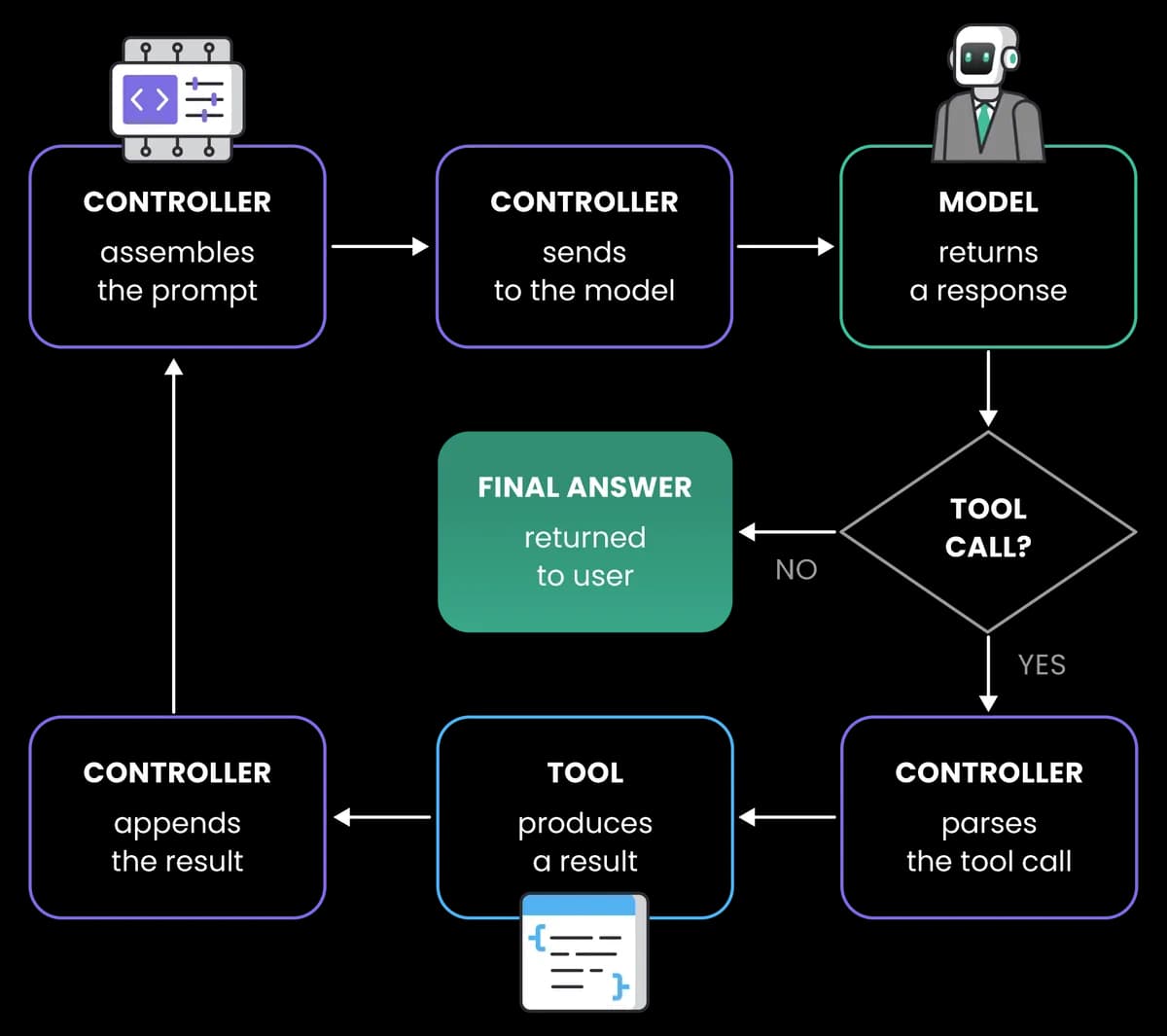
An agent is what you get when you drop an LLM into a control loop and give it two new powers: it can call external tools, and it can work toward a goal across multiple steps of reasoning.
The loop at the center of an agent usually gets described in three beats: reason, act, observe. You give the model a goal. It reasons about what to do next. It asks to call a tool, which might be a web search, a database query, a function in your code, or another model. The tool runs. The result comes back to the model as new context. The model looks at the result, reasons again, and either calls another tool or decides the goal is done.
That loop is the difference between a chatbot and an agent. A chatbot answers. An agent does. Ask a chatbot “what's the weather in Paris?” and it'll tell you it doesn't have real-time data. Ask an agent with a weather tool the same thing, and it'll call the API and give you the actual forecast. From a capability standpoint, that gap is enormous.
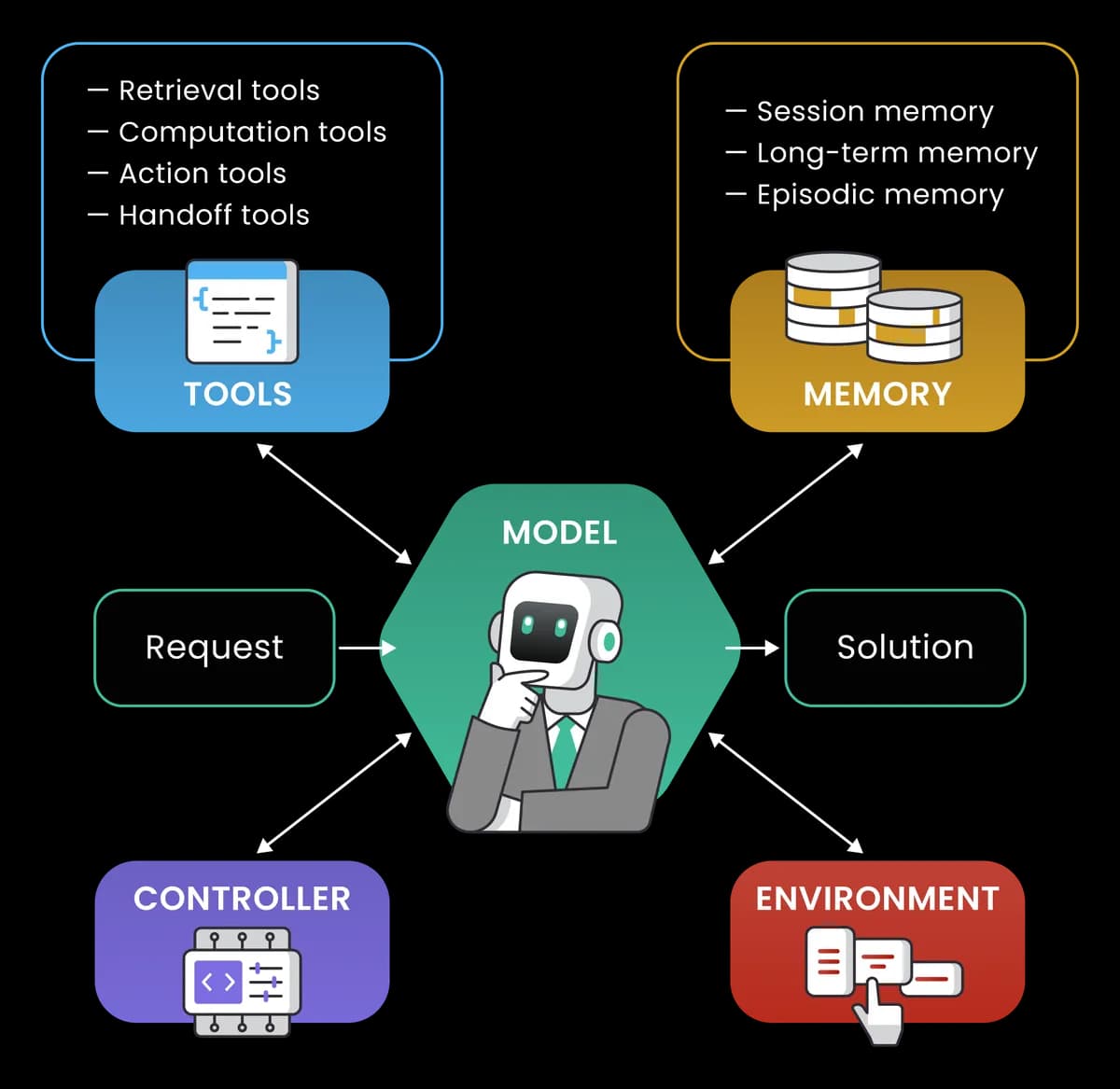
A few pieces make an agent work in practice:
- A model doing the reasoning.
- A set of tools the model can call, each one described in a format the model understands.
- Some kind of memory, which might be as simple as the conversation history or as involved as a vector database of past interactions.
- A controller (or planner) that runs the loop, enforces limits, and decides when the agent is done.
- An environment the agent perceives and affects through its tools.
None of those pieces is new. What's new is putting them together with a model capable enough to act as the reasoning core. The results can do things that would have seemed like science fiction five years ago. They can also fail in ways that are surprising, embarrassing, and sometimes costly.
The mental model: layers, with one exception
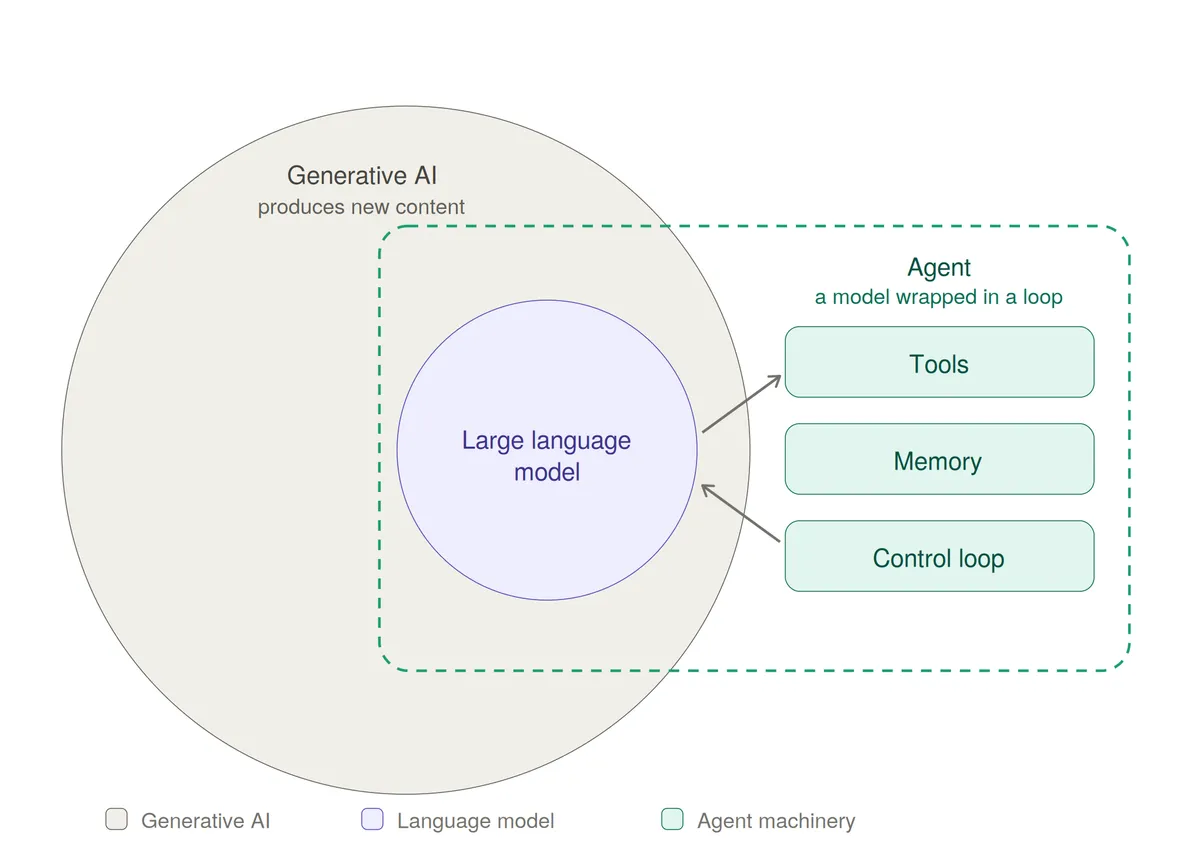
Three terms get used almost interchangeably: generative AI, large language models, and agents. They are related, though one of them fits differently from the other two.
Two of them do nest cleanly. Generative AI is the broad class of systems that produce new content. A large language model is one of them, the kind that produces text. The smaller sits wholly inside the larger.
The agent is where the picture changes. An agent is a system built around a model. Take a language model, give it tools it can call, a way to read the results, some memory, and a loop that keeps running until a goal is met, and you have an agent. The model decides what to say or do next. The tools, the memory, and the loop carry those decisions out. The generating happens only in the model. The agent is larger than the model it runs on, and it holds the model inside it.
The layer you are dealing with decides what you should expect and what you should ask. If you are looking at a generative image tool, questions about context windows and tool calls do not apply. If you are looking at a writing assistant running on a language model, asking about agent orchestration is jumping ahead. If you are looking at an actual agent, asking only about the model leaves most of the system out, since the tools, the memory, and the loop weigh as much as the model does.
Why the difference matters
Here's a concrete example. A vendor offers to build your company “an AI.” What are you actually buying?
If what they deliver is a generative model fine-tuned on your documents, you've got a text tool that can draft emails or summaries. Useful, but limited. It can't look anything up, can't verify its own claims, can't take any action for you. If what they deliver is an LLM with retrieval, you've got a system that can answer questions grounded in your data. Better, but still reactive. If what they deliver is an agent, you've got something that can plan, call tools, update records, and act in the world. A lot more powerful. Also a lot more capable of causing trouble when it's wrong.
Three layers, three risk profiles, three cost structures, three engineering challenges, three sets of expectations. Treating them as one undifferentiated thing, which most of the public conversation still does, leads to over-investing in simple problems and under-investing in the hard ones.
Where to go next
This article has been all about vocabulary. It's meant to give you the words you need to follow more technical conversations without getting lost. The next step, if you're going to actually work with any of these systems, is to look more closely at agents specifically: how they're built, what patterns have emerged for building them well, and why going from a working demo to a production deployment is a bigger leap than most teams expect.