Integrating Diagrid Catalyst with LangGraph
LangGraph orchestrates the graph; it doesn't keep it alive when the process dies. Diagrid Catalyst wraps your compiled graph so that every node becomes a durable activity with automatic recovery, tracing, and built-in identity.
A LangGraph agent is running in production. Traffic ramps up. A pod gets recycled during a routine deployment, and a run that was three nodes deep stops advancing. The state is fine. LangGraph wrote a checkpoint after the last completed step, and it sits in Postgres exactly where it should. What's missing is anything that turns that checkpoint back into a running graph.
Whatever new process comes up to replace the dead one has no idea the run is there, much less that it's waiting to resume. Nothing in the framework polls for orphaned runs. Nothing supervises the process that disappeared. The run is still queryable. It is not failed. It is stranded.
This is the failure mode every team that ships open-source LangGraph past a notebook eventually meets. The graph logic is sound. The prompts work. The tools resolve. And then production happens. A deployment cycles a node mid-run, a transient network error takes out a tool call, an OOM kill removes the process, and the run quietly stalls without anything noticing. There is no automatic resumption. Nothing signals that something is wrong.
The question this article answers isn't whether LangGraph is a good framework. It is. The question is what you have to add to LangGraph to run it in production, and why the things you have to add aren't really LangGraph's job to provide.
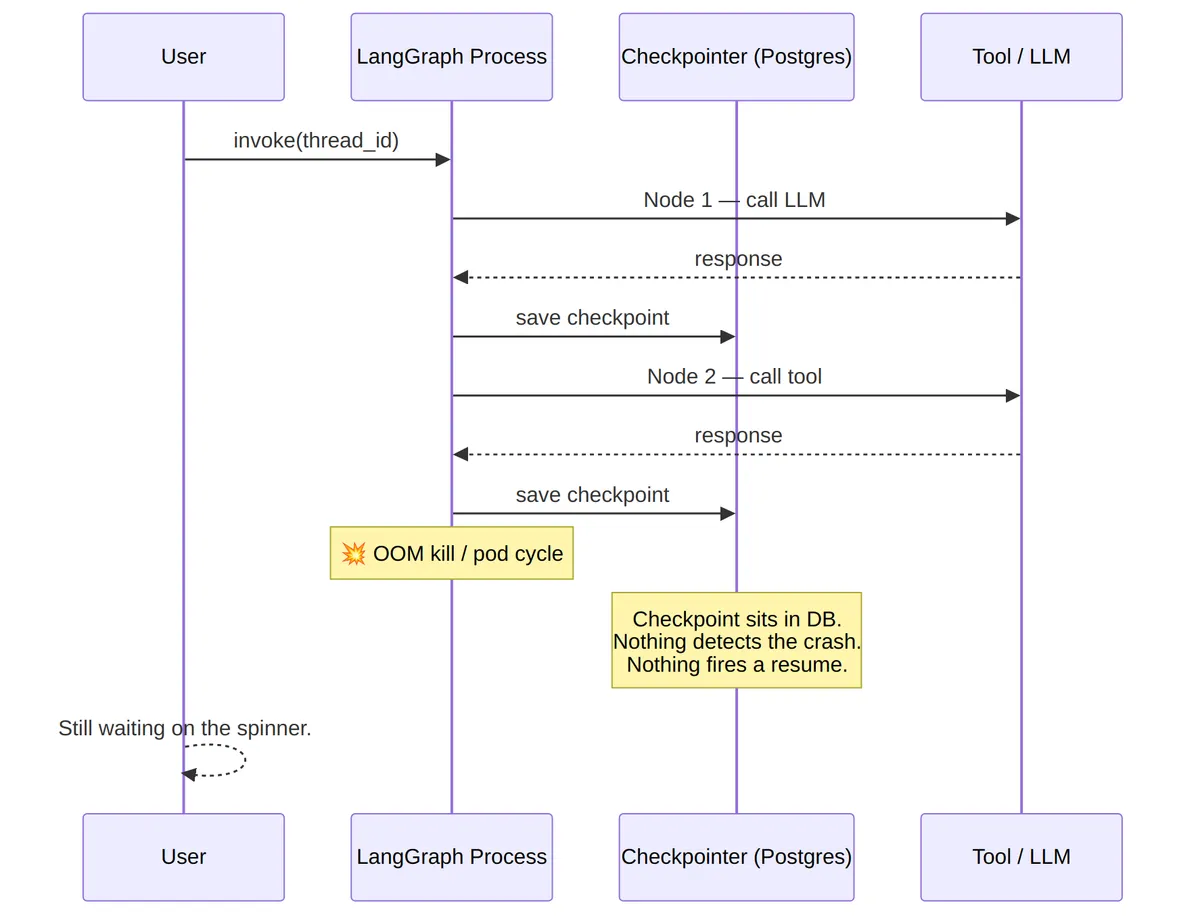
Fig 1: A LangGraph run after the process disappears. The checkpoint persists. Nothing notices.
What LangGraph was built for, and what it wasn't
LangGraph is excellent at graph-based orchestration of agent logic. Nodes, edges, conditional routing, parallel execution, typed shared state. This is the right abstraction for a 2026 agent, and it is a significant improvement over linear chain DSLs (Domain-Specific Language) that could not express looping, branching, or human-in-the-loop interrupts cleanly. If you are running LangGraph today, you are running it because the graph model fits the shape of the work.
Where the framework gets misread is in what its checkpointing actually does. LangGraph saves state at each superstep boundary. The graph commits a full state snapshot after every superstep completes, the checkpointer persists it, and the next superstep starts from that known good state. That is real. What it is not is autonomous durable execution.
A checkpoint is a snapshot. Nothing in the framework checks whether the process holding the next node is still alive, reissues the run if it disappears, or coordinates across instances to ensure a thread is not picked up by two workers simultaneously. The checkpoint preserves state, but it does not restart execution.
This becomes a production problem when a process crashes. There is no supervisor, watchdog, or heartbeat to detect the failure. The workflow remains idle until something external notices, and resumption must be implemented by the developer. At scale, that means building failure detection, retries, and distributed locking. None of that ships with the framework, and none of it is optional for reliable execution.
Where LangGraph reaches its ceiling in production
The gap shows up as three distinct surfaces. They are not the same problem, and they are not solved by the same fix.

Fig 2: The three surfaces where a raw LangGraph deployment falls short of production.
Durability. LangGraph's default checkpointer, InMemorySaver, is ephemeral and local. When the process dies, the state dies with it, which is fine for notebooks and unacceptable for anything else. Swap it for PostgresSaver and you get persistence. Checkpoints survive restarts, and a returning thread can pick up where it left off.
What persistence does not give you is automatic recovery. The state is on disk, but nothing fires a resume. If the process that was driving the graph is gone, the checkpoint will sit in Postgres indefinitely. Resumption is a manual operation which will be an external caller, a cron job, a scheduler you have built, and at multi-worker scale, you also own preventing two of those callers from picking up the same thread_id at the same time. Persistence is the easy half. The supervisor that turns persistence into recovery is the half you have to build.
The second is observability. LangGraph has no built-in observability layer. Per-step traces, input and output inspection, full execution history these are not in the framework, and the recommended path is to bolt on a separate tool (LangSmith, Langfuse) that you choose, configure, instrument, and operate yourself. The wiring is not exotic, but it is wiring you own. When a run fails, what you see is whatever you remembered to log, and the production teams that have lived through a late-night incident know exactly how thin that turns out to be in practice.
The third is security. Between agents, between an agent and a tool, between a tool and a downstream service, there is no cryptographic identity in the framework, no mTLS. Nodes call each other and call out to tools with whatever auth boilerplate the developer wrote into the application code. The moment an agent talks to anything outside its own process, the security model is whatever the developer remembered to add.
That is not a criticism of LangGraph but a matter of scope. The framework's scope is the graph. The security requirements of a production system extend beyond the graph.
What production-grade agent infrastructure actually requires
Step back from the framework, and the bar becomes clear. Three things must be true for an agent to run in production without becoming an incident waiting to happen.
- Automatic recovery: Not just state persistence, but failure detection and resumption across instances without a human in the loop. The supervisor, the heartbeat, the lease, the placement service that guarantees a single workflow is owned by exactly one worker at a time. A state that survives a crash is necessary but not sufficient. The system has to notice the crash and act on it.
- End-to-end observability: Per step visibility into inputs outputs and execution history available by default not reconstructed from logs after the fact. This matters for practical debugging. When a 14 step agent fails on step 9 you need to know the input to step 9 what the model returned what the tool did with it and what the resulting state diff looked like without instrumenting each node after the run is already lost.
- Identity and access control: Every agent and every tool call carries a verifiable identity, authenticated and authorized at the data plane rather than in application code. This is the difference between “we trust that the developer wrote the auth header correctly in every tool call” and “the runtime refuses any call that is not signed by an identity it can verify.” One of those is a security posture. The other is a hope.
For two of the three, LangGraph doesn't claim otherwise. For the first, it does, which is the gap this piece keeps landing on.
What Diagrid Catalyst adds, and what stays the same
Diagrid Catalyst is a reliable and secure platform for running agentic workloads in production, with the Dapr runtime, state stores, and message brokers managed for you. The integration with LangGraph is deliberately narrow since your graph code does not change. You define your StateGraph the same way. You compile it the same way. The integration point is a single wrapper DaprWorkflowGraphRunner, that takes the compiled graph and runs it on top of Dapr Workflows. Each node becomes a durable workflow activity. Everything else about how you wrote the graph remains the same.
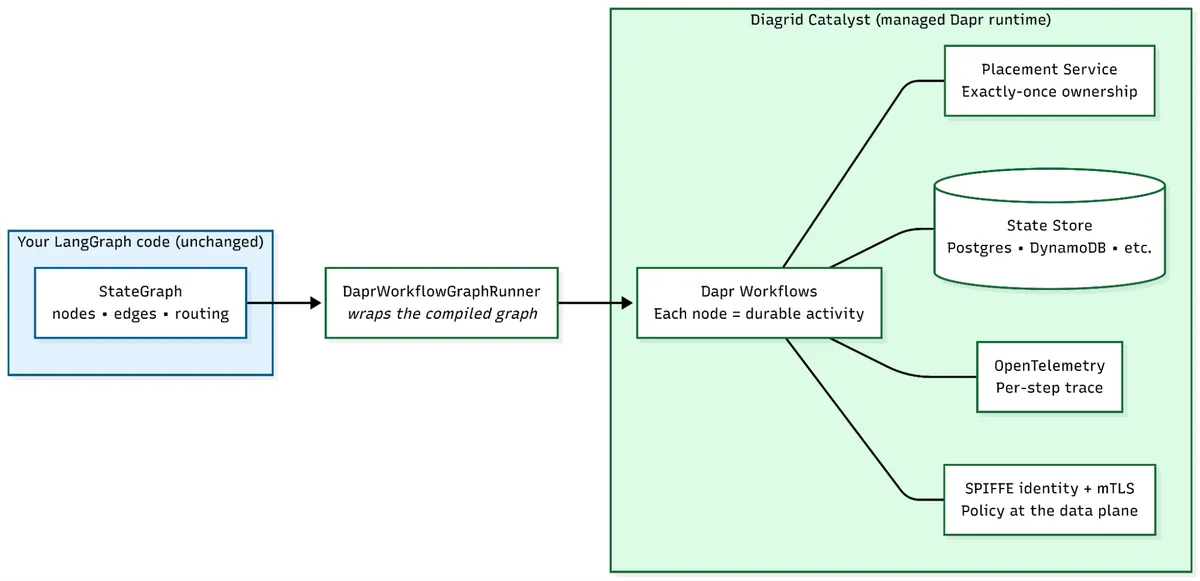
Fig 3: DaprWorkflowGraphRunner wraps the compiled graph. The graph stays yours; the infrastructure underneath moves into Diagrid Catalyst.
What changes is what happens underneath. The three gaps named above get closed at the infrastructure layer, not by asking you to rewrite your agent.
Durability becomes a property of the runtime. State is persisted to a customer managed store after every node completes and Dapr's actor placement service ensures each workflow is processed by exactly one instance so no two workers ever pick up the same run. When a process crashes, the workflow is automatically recovered and resumed on another instance from the last completed activity. Completed nodes do not re-run. The LLM calls you already paid for are not re-executed. Resumption is not something you trigger; it is something the runtime does.
Observability becomes a property of the runtime as well. Every workflow run has a per-step execution history with inputs, outputs, and timing, available out of the box through Dapr's OpenTelemetry-based tracing. You do not instrument nodes. You do not stand up a separate tracing stack. You read the trace.
Security is enforced at the data plane. Every agent receives a SPIFFE-based cryptographic identity. Communication between components is encrypted with automatic mTLS. Access policies which agents can call which tools and which tools can talk to which downstream services are defined declaratively and enforced by the runtime sidecar not by auth code inside the graph. Tool calls that violate policy are blocked before the agent node code ever runs.
Your graph stays the same. The infrastructure underneath stops being your problem.
Why this matters at scale
One agent failing in a demo is an inconvenience. A hundred agents failing mid run in production with no automatic recovery is an operational crisis and a budgetary one. Each failure that gets retried without thread aware resume restarts the graph from the top re-executing every LLM call it had already paid for. Durable execution at the activity level means the failed step retries not the whole run. The token bill stops compounding with the failure rate.
The cost case is concrete enough to put on a CFO's desk, but the operational case is more visceral. Running a hundred LangGraph agents under realistic chaos conditions such as process crashes, OOM kills, rolling deployments, infrastructure failures, and guaranteeing every run completes is not a thing a custom retry loop and a Postgres checkpointer can do reliably.
The mechanism that does it is durable execution backed by a placement service, a state store, and a supervisor that runs underneath the application code. That mechanism is what Dapr Workflows is, and what Diagrid Catalyst makes operable without standing up the underlying infrastructure yourself.
For platform teams, there is a second point worth naming. Diagrid Catalyst is framework-agnostic. The same durability and security primitives that wrap a LangGraph graph also wrap CrewAI crews, OpenAI Agents, Strands agents, Microsoft Agent Framework agents, and Dapr Agents. One platform decision covers the whole portfolio, instead of one platform decision per framework. The graph model and the agent framework you pick get to be a team-by-team choice. The reliability and security floor underneath them does not have to be.
Where to go next
LangGraph is the right abstraction for the graph. Diagrid Catalyst is the right abstraction for the production infrastructure that LangGraph does not include durability, observability, and security without requiring a rewrite of the graph you already have. The integration is a wrapper, not a migration.
The fastest way to see this in practice is the Dapr Agents course at Diagrid AI University, which walks through durability, observability, and multi-agent workflows hands-on.
If you are ready to wire this up against your own graph, the LangGraph quickstart in the Diagrid Catalyst docs is the right entry point.
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.