Dapr for Spring Boot
With Spring I/O happening this week in Barcelona, Spain, I wanted to share some news and direction about how the Dapr project can be used with Spring Boot to build better, more resilient, and leaner cloud-native applications.
Mauricio Salatino
Staff Software Engineer
With Spring I/O happening this week in Barcelona, Spain, I wanted to share some news and direction about how the Dapr project can be used with Spring Boot to build better, more resilient, and leaner cloud-native applications.
TLDR:
- Today, Spring Boot applications run on Cloud-Native runtimes, Kubernetes, or container services provided by cloud vendors.
- The Spring Boot programming model is the most adopted way to build distributed applications in Java. We can close the gap between cloud-native runtimes and Spring Boot applications while at the same time reducing an application’s footprint and increasing portability.
- The Dapr project complements Spring Boot to provide a unified and portable cross-runtime experience, including local development, Kubernetes, and container runtimes. This synergy helps platform teams enable developers with best practices and simplified ways to access infrastructure across environments. Leveraging Testcontainers, we can provide a local development experience integrated with the Spring Boot ecosystem.
- Fewer application dependencies (like the Kafka client, RabbitMQ client, Redis client, and database drivers) also mean less cognitive load for team members. Fewer dependencies mean fewer things to learn to be productive.
A bit of history
I’ve been working with Java for more than 15 years now. I started my journey with the J2EE (Java Enterprise Edition) spec and jumped into Java EE 5 with JBoss Application server and Glassfish. The Java community is well known for its standardization initiatives, defining specs that tackle the needs of most enterprise applications. I used the JBoss application server to implement cross-cutting concerns for enterprise architectures. such as observability, resiliency, and scalability. Standard specifications, like Jakarta EE, are still very prevalent in Java communities. However, over the last five years, smaller groups of specifications, such as Microprofile (focused on single application/service concerns), have become more relevant to Java developers building microservices in distributed applications.
In parallel, Spring Boot (over 10 years old now) and other frameworks started changing their paradigm, eliminating then need for application servers and using smaller runtimes, mostly using servlet containers such as Tomcat to run a single application/service. This aligned with 12factor.net's approach using applications and containers, which changed how people architect, build, and deploy cloud-native (or distributed) applications.
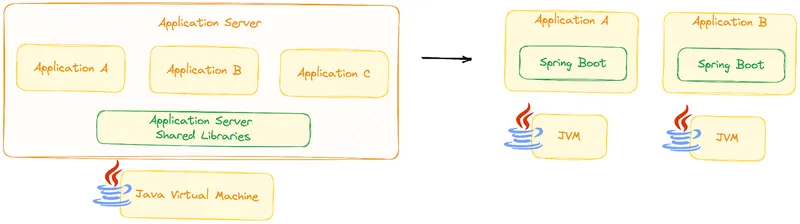
The focus changed from application servers designed to run multiple applications to single application runtimes. When using frameworks like Spring Boot, developers can think of a single service per Spring Boot application. In a way, this simplified development tasks, but something was still missing: cross-cutting concerns. Previously taken care of by a unified runtime, they were now, in part, the responsibility of each service. While you could wire up multiple applications together manually, developers needed much more; that's the reason Spring Cloud was born.
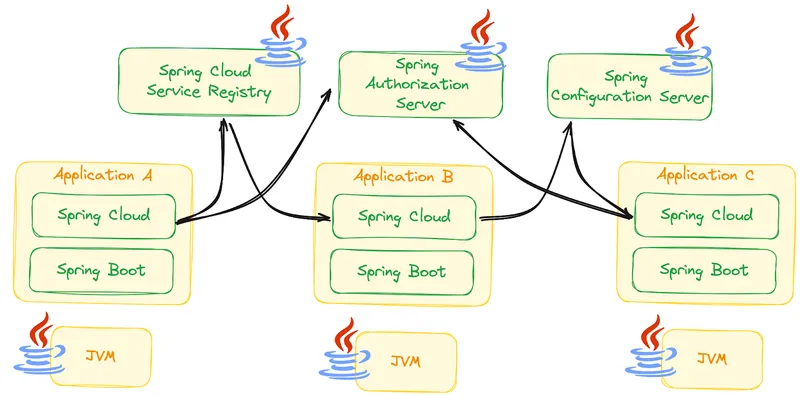
Wrapping around components open-sourced by Netflix, Spring Cloud provided the core functionality for building distributed systems. With building blocks for Service Discovery, service-to-service resiliency, an authentication server, and configuration service, among others, Spring Cloud offers libraries and standalone components to create your own distributed runtime. Notice that developers now need to care about these standalone components and ensure that your applications are aware of them by including some libraries in charge of handling client-side concerns, such as retry mechanisms and circuit breakers.
With the rise of containers, Spring Boot developers now had to figure out how to containerize their applications. They faced three significant challenges: excessive resource consumption (memory and CPU), larger application size, and slow startup times. Compared with other tech stacks, the resource consumption of the Java Virtual Machine wasn’t optimized for containers [blog on optimizing Java for containers], and the inclusion of frameworks and libraries significantly increased applications' size..
These challenges became even more apparent with more complex applications being deployed on Kubernetes. It is hard not to draw parallels between Kubernetes and Application Servers (read the blog from 2018 from Rafael Benevides, a good friend, clearly coming from a Java background - https://developers.redhat.com/blog/2018/06/28/why-kubernetes-is-the-new-application-server) as both provide a runtime for multiple applications. Early on, a team of Java developers from Red Hat (https://fabric8.io), created the first Java Kubernetes API client and a bunch of integrations with Spring Boot, which later was donated as the Spring Cloud Kubernetes project. While these integrations helped developers to interact with the Kubernetes APIs, there was a big overlap and confusion between some Spring Cloud components and core Kubernetes services.
In 2018, it was now common to see Istio (a service mesh) promoted as the missing layer in Kubernetes to have cross-cutting concerns handled by the runtime and not the applications themselves. However, Istio has no application-level services for application developers to use. Contrast with Application Servers, and even Servlet Containers, where application developers had access to JNDI (Java Naming and Directory Interface) for service discovery and abstractions, such as Enterprise Java Beans for transparent and resilient service-to-service communications and Message-driven Beans to exchange asynchronous messages across applications.
In 2019, Microsoft announced the Dapr project – which today ranks among the most popular CNCF projects. Dapr stands for “Distributed Application Runtime,”, a project designed to help developers to build better distributed applications. Dapr is all about providing developers with application-level APIs that abstract application code from infrastructure while simultaneously providing applications with cross-cutting concerns such as resiliency, observability, and security. A critical difference between Dapr and some Spring Cloud libraries is that Dapr runs outside your Spring Boot application, not as a dependency. Similar to application servers and service meshes in the Kubernetes era, the idea is to push these concerns closer to the application runtime and avoid adding/changing our applications.
Pushing these concerns down to the application runtime helps applications to be simpler and smaller, as fewer libraries must be bundled in with the application code. Applications in any programming language can access the Dapr APIs using HTTP or gRPC calls.

From my perspective, Dapr flew under Java developers’ radars because it works for every language, so it wasn’t Java-specific, but it was also created by Microsoft. Back then, Microsoft wasn’t that involved in the Java community. While some folks in the Java community reviewed the Dapr project (Baeldung’s Spring Blog, Marteen Mulders Blog Series [1., [2., and [3. ), using Dapr from Spring Boot applications never felt compelling. I’ve been working with Dapr for over a year now, and I think that there are two main reasons why now is the right time to look at the combination of Dapr and Spring Boot seriously:
- Kubernetes and container runtimes (cloud provider services such as Google Cloud Run, Azure Container Apps, and AWS container services) have become our de facto Java application runtimes. We cannot rely on language-specific frameworks and solutions that will be hard to integrate with other stacks. If we can help developers create simpler, smaller, and optimized Java applications for these runtimes, developers can spend more time focusing on their applications’ features rather than deciding which libraries and frameworks they need to use.
- Making sure that our applications can run and be debugged locally, without pushing developers to learn Kubernetes or cloud provider specific tools, is key to accelerate development productivity. If these applications can be moved across environments without any code changes, we can go one step forward to help operation teams to wire available infrastructure for each environment in a consistent way.
For the rest of this article we will look at how Spring Boot developers can use Dapr without changing their day-to-day practices. We will look at new integrations that bring Dapr closer to the Spring Boot ecosystem and improve the local development experience for distributed applications.
Today, Kubernetes and Cloud-Native Runtimes
Today, if you want to work with the Dapr project, no matter the programming language you are using, the easiest way is to install Dapr into a Kubernetes Cluster. I would argue that Kubernetes and container runtimes are the most common runtime for our Java applications today, however asking Java developers to work and run their application on a Kubernetes Cluster for their day-to-day tasks might be way out of the comfort zone. Training a large team of developers on using Kubernetes can take a while, and they will need to learn how to install tools like Dapr on their clusters.

If you are a Spring Boot developer, you probably want to code, run, debug, and test your Spring Boot applications locally. For this reason, we created a local development experience for Dapr, teaming up with the Testcontainers folks, now part of Docker.
As a Spring Boot developer, you can use the Dapr APIs without a Kubernetes cluster or needing to learn how Dapr works in the context of Kubernetes.
This test shows how Testcontainers provisions the Dapr runtime by using the `@ClassRule` annotation, which is in charge of bootstrapping the Dapr runtime so your application code can use the Dapr APIs to save/retrieve state, exchange asynchronous messages, retrieve configurations, create workflows, and use the Dapr actor model.
@ClassRule
public static DaprContainer daprContainer = new DaprContainer("daprio/daprd")
.withAppName("dapr-app")
.withAppPort(8081)
.withAppChannelAddress("host.testcontainers.internal");
@Test
public void testDaprAPIs() throws Exception {
try (DaprClient client = (new DaprClientBuilder()).build()) {
String value = "value";
// Save state on the STATE_STORE_NAME specified
client.saveState(STATE_STORE_NAME, KEY, value).block();
…
// Get the state back from the STATE_STORE_NAME
State<String> retrievedState = client.getState(STATE_STORE_NAME, KEY,
String.class).block();
// Publish an Event to the PUBSUB_NAME broker in the PUBSUB_TOPIC_NAME
client.publishEvent(
PUBSUB_NAME,
PUBSUB_TOPIC_NAME,
message).block();
}
}How does this compare to a typical Spring Boot application? Let’s say you have a distributed application that uses Redis, PostgreSQL, and RabbitMQ to persist and read state, and Kafka to exchange asynchronous messages. You can find the code for this application here: https://github.com/salaboy/example-voting-app (under the java/ directory, you can find all the Java implementations).
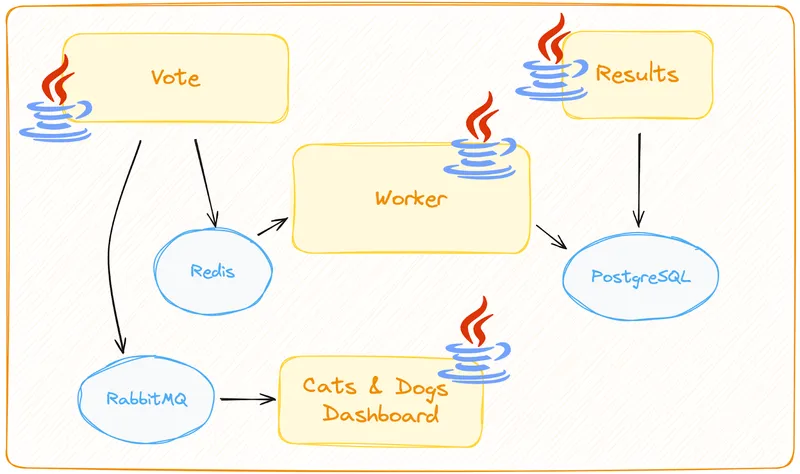
Your Spring Boot applications will need to have not only the Redis client but also the PostgreSQL JDBC driver and the RabbitMQ client as dependencies. On top of that, it is pretty standard to use Spring Boot abstractions, such as Spring Data KeyValue for Redis, Spring Data JDBC for PostgreSQL, and Spring Boot Messaging RabbitMQ. These abstractions and libraries elevate the basic Redis, relational database, and RabbitMQ client experiences to the Spring Boot programming model. Spring Boot will do more than just call the underlying clients. It will manage the underlying client lifecycle and help developers implement common use cases while promoting best practices under the covers.
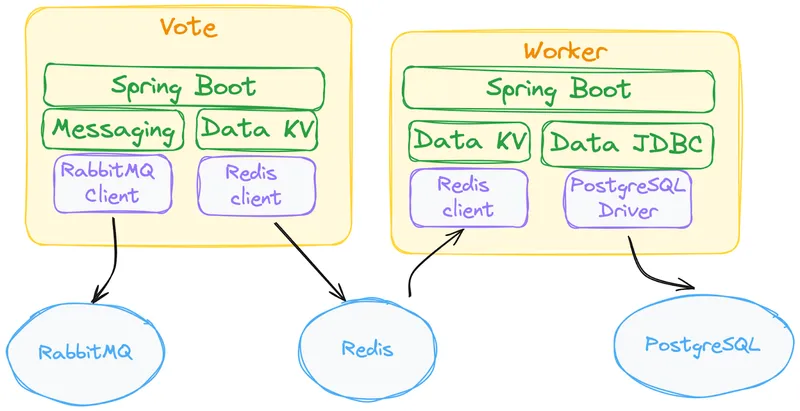
If we look back at the test that showed how Spring Boot developers can use the Dapr APIs, the interactions will look like this:
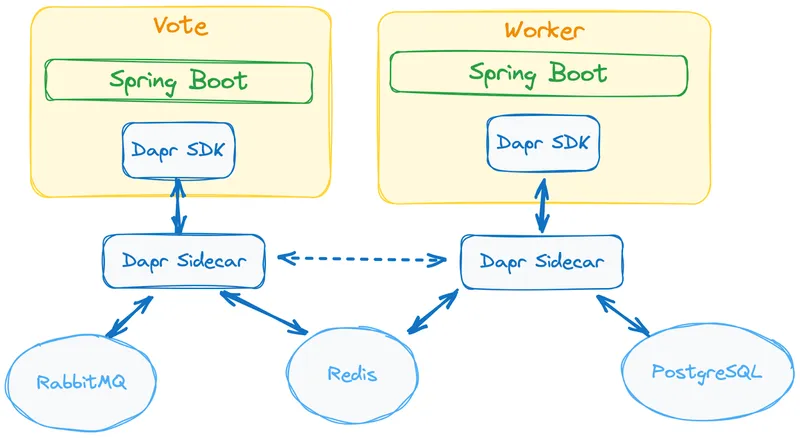
In this diagram, the Spring Boot application only depends on the Dapr APIs. In both, the unit test using the Dapr APIs shown above and the previous diagram, instead of connecting to the Dapr APIs directly using HTTP or gRPC requests, we have chosen to use the Dapr Java SDK. No RabbitMQ, Redis clients, or JDBC drivers were included in the application classpath.
This approach of using Dapr has several advantages:
- The application has fewer dependencies, so it doesn’t need to include the Redis or RabbitMQ client. The application size is not only smaller but less dependent on concrete infrastructure components that are specific to the environment where the application is being deployed. Remember that these clients’ versions must match the component instance running on a given environment. With more and more Spring Boot applications deployed to cloud providers, it is pretty standard not to have control over which versions of components like databases and message brokers will be available across environments. Developers will likely run a local version of these components using containers, causing version mismatches with environments where the applications run in front of our customers.
- The application doesn’t create connections to Redis, RabbitMQ, or PostgreSQL. Because the configuration of connection pools and other details closely related to the infrastructure and these components are pushed away from the application code, the application is simplified.
- A new application developer doesn’t need to learn how RabbitMQ, PostgreSQL, or Redis works. The Dapr APIs are self-explanatory: if you want to save the application’s state, use the `saveState()` method. If you publish an event, use the `publishEvent()` method. Developers using an IDE can easily check which APIs are available for them to use.
- The teams configuring the cloud-native runtime can use their favorite tools to configure the available infrastructure. If they move from a self-managed Redis instance to a Google Cloud In-Memory Store, they can swap their Redis instance without changing the application code. If they want to swap a self-managed Kafka instance for Google PubSub or Amazon SQS/SNS, they can shift Dapr configurations.
But, you ask: what is that DaprClient client = new DaprClientBuilder().build(); that doesn’t look like Spring Boot. And what about those APIs, `saveState/getState` and `publishEvent`. What about subscriptions? How do you consume an event? Can we elevate these API calls to work better with Spring Boot so developers don’t need to learn new APIs?
Tomorrow, a unified cross-runtime experience
In contrast with most technical articles, the answer here is not “it depends”. Of course, the answer is YES. We can follow the Spring Data and Messaging approach to provide a richer Dapr experience that integrates seamlessly with Spring Boot. This, combined with a local development experience (using Testcontainers), can help teams design and code applications that can run quickly and without changes across environments (local, Kubernetes, cloud provider).
If you are already working with Redis, PostgreSQL, and/or RabbitMQ, you are most likely using Spring Boot abstractions Spring Data and Spring RabbitMQ/Kafka/Pulsar for asynchronous messaging.
Spring Data KeyValue, check this blog post for more details: https://www.baeldung.com/spring-data-key-value
@Bean
public KeyValueOperations keyValueTemplate() {
return new KeyValueTemplate(keyValueAdapter());
}
@Bean
public KeyValueAdapter keyValueAdapter() {
return new MapKeyValueAdapter(WeakHashMap.class);
}
Employee employee = new Employee(1, "Mile", "IT", "5000");
keyValueTemplate.insert(employee);
// To find an Employee by ID:
Optional<Employee> savedEmployee = keyValueTemplate
.findById(id, Employee.class);For asynchronous messaging we can take a look at Spring Kafka, Spring Pulsar, and Spring AMQP (RabbitMQ) (https://spring.io/guides/gs/messaging-rabbitmq ), which all provide a way to produce and consume messages.
Producing messages with Kafka is this simple:
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String msg) {
kafkaTemplate.send(topicName, msg);
}Consuming Kafka messages is extremely straightforward too:
@KafkaListener(topics = "topicName", groupId = "foo")
public void listenGroupFoo(String message) {
System.out.println("Received Message in group foo: " + message);
}For RabbitMQ, we can do pretty much the same:
@Autowired
private final RabbitTemplate rabbitTemplate;And then to send a message:
rabbitTemplate.convertAndSend(
topicExchangeName, "foo.bar.baz", "Hello from RabbitMQ!");To consume a message from RabbitMQ, you can do:
String foo = (String) rabbitTemplate.receiveAndConvert("myqueue");Elevating Dapr to the Spring Boot developer experience
Now let’s take a look at how it would look with the new Dapr Spring Boot starters:
Let’s take a look at the DaprKeyValueTemplate:
@Autowired
private final DaprKeyValueTemplate keyValueTemplate;Let’s now store our Vote object using the KeyValueTemplate.
Vote vote = new Vote("vote", voterId, selectedOption, voterId);
// Store the vote
keyValueTemplate.insert(vote);Let’s find all the stored votes by creating a query to the KeyValue store:
KeyValueQuery<String> keyValueQuery = new KeyValueQuery<String>("’type’ == ‘vote’");
Iterable<Vote> votes = keyValueTemplate.find(keyValueQuery, Vote.class);Now, why does this matter? The `DaprKeyValueTemplate`, implements the KeyValueOperations interfaces provided by Spring Data KeyValue, which is implemented by tools like Redis, MongoDB, Memcached, PostgreSQL, and MySQL, among others. The big difference is that this implementation connects to the Dapr APIs and does not require any specific client. The same code can store data in Redis, PostgreSQL, MongoDB, and cloud provider-managed services such as AWS DynamoDB and Google Cloud Firestore. Over 30 data stores are supported in Dapr, and no changes to the application or its dependencies are needed.
Similarly, let’s take a look at the `DaprMessagingTemplate`.
@Autowired
private final DaprMessagingTemplate<Vote> messagingTemplate;Let’s publish a message/event now:
messagingTemplate.send(voteProperties.topic(), vote);To consume messages/events, we can use the annotation approach similar to the Kafka example:
@Topic(name = topicName, pubsubName = pubSubName)
@PostMapping("/subscribe")
public void handleMessages(@RequestBody CloudEvent<Vote> event) {
LOG.info("++++++CONSUME {}------", event);
}An important thing to notice is that out-of-the-box Dapr uses CloudEvents to exchange events (other formats are also supported), regardless of the underlying implementations. Using the @Topic annotation, our application subscribes to listen to all events happening in a specific Dapr PubSub component in a specified Topic.
Once again, this code will work for all supported Dapr PubSub component implementations such as Kafka, RabbitMQ, Apache Pulsar, and cloud provider-managed services such as Azure Event Hub, Google Cloud PubSub, and AWS SNS/SQS.
https://docs.dapr.io/reference/components-reference/supported-pubsub/
Combining the DaprKeyValueTemplate and DaprMessagingTemplate gives developers access to data manipulation and asynchronous messaging under a unified API, which doesn’t add application dependencies, and it is portable across environments, as you can run the same code against different cloud provider services.
While this looks much more like Spring Boot, more work is required. On top of Spring Data KeyValue, the Spring `Repository` interface can be implemented to provide a CRUDRepository experience. There are also some rough edges for testing, and documentation is needed to ensure developers can get started with these APIs quickly.
Advantages and trade-offs
As with any new framework, project, or tool you add to the mix of technologies you are using, understanding trade-offs is crucial in measuring how a new tool will work specifically for you.
One way that helped me understand the value of Dapr is to use the 80% vs 20% rule. Which goes as follows:
- 80% of the time, applications do simple operations against infrastructure components such as message brokers, key/value stores, configuration servers, etc. The application will need to store and retrieve state and emit and consume asynchronous messages just to implement application logic. For these scenarios, you can get the most value out of Dapr.
- 20% of the time, you need to build more advanced features that require deeper expertise on the specific message broker that you are using or to write a very performant query to compose a complex data structure. For these scenarios, it is ok not to use the Dapr APIs, as you probably require access to specific underlying infrastructure features from your application code.
It is common when we look at a new tool to generalize it to fit as many use cases as we can. With Dapr, we should focus on helping developers when the Dapr APIs fit their use cases. When the Dapr APIs don’t fit or require specific APIs, using provider-specific SDKs/clients is OKokay. By having a clear understanding of when the Dapr APIs might be enough to build a feature, a team can design and plan in advance what skills are needed to implement a feature. For example, do you need a RabbitMQ/Kafka or a SQL and domain expert to build some advanced queries?
Another mistake we should avoid is not considering the impact of tools on our delivery practices. If we can have the right tools to reduce friction between environments and if we can enable developers to create applications that can run locally using the same APIs and dependencies required when running on a cloud provider.
With these points in mind let’s look at the advantage and trade-offs:
- Advantages:
- Concise APIs to tackle cross-cutting concerns and access to common behavior required by distributed applications. This enables developers to delegate to Dapr concerns such as resiliency (retry and circuit breaker mechanisms), observability (using OpenTelemetry, logs, traces & metrics) and security (certificates and mTLS).
- With the new Spring Boot integration, developers can use the existing programming model to access functionality
- With the Dapr and Testcontainers integration, developers don’t need to worry about running or configuring Dapr, or learning other tools that are external to their existing inner development loops. The Dapr APIs will be available for developers to build, test and debug their features locally.
- The Dapr APIs can help developers to save time when interacting with infrastructure. For example, instead of pushing every developer to learn about how Kafka/Pulsar/RabbitMQ works, they just need to learn how to publish and consume events using the Dapr APIs.
- Dapr enables portability across cloud-native environments, allowing your application to run against local or cloud managed infrastructure without any code changes. Dapr provides a clear separation of concerns to enable operations/platform teams to wire infrastructure across a wide range of supported components.
- Introducing abstraction layers, such as the Dapr APIs, always come with some trade-offs:
- Dapr might not be the best fit for all scenarios. For those cases, nothing stops developers from separating more complex functionality that requires specific clients/drivers into separate modules or services.
- Dapr will be required in the target environment where the application will run. Your applications will depend on Dapr to be present and the infrastructure needed by the application wired up correctly for your application to work. If your operation/platform team is already using Kubernetes, Dapr should be easy to adopt as it is a quite mature CNCF project with over 3,000 contributors.
- Troubleshooting with an extra abstraction between our application and infrastructure components can become more challenging. The quality of the Spring Boot integration can be measured on how well errors are propagated to developers when things go wrong.
I know that advantages and trade-offs depend on your specific context and background, feel free to reach out if you see something missing in this list.
Summary and next steps
Covering the Dapr Statestore (KeyValue) and PubSub (Messaging) is just the first step, as adding more advanced Dapr features into the Spring Boot programming model can help developers access more functionality required to create robust distributed applications. On our TODO list, Dapr Workflows for durable executions is coming next, as providing a seamless experience to develop complex, long-running orchestration across services is a common requirement. The example application that we are presenting at Spring I/O with Thomas Vitale uses workflows if you want to check it out.
One of the reasons why I was so eager to work on the Spring Boot and Dapr integration is that I know that the Java community has worked hard to polish their developer experiences focusing on productivity and consistent interfaces. I strongly believe that all this accumulated knowledge in the Java community can be used to take the Dapr APIs to the next level. By validating which use cases are covered by the existing APIs and finding gaps, we can build better integrations and automatically improve developers’ experiences across languages.
You can find all the source code for the example we presented at Spring I/O here: https://github.com/salaboy/example-voting-app (java/ directory).
We expect to merge the Spring Boot and Dapr integration code to the Dapr Java SDK to make this experience the default Dapr experience when working with Spring Boot. Documentation will come next, and the Spring I/O recordings will be available after the conference.
If you want to contribute or collaborate with these projects and help us make Dapr even more integrated with Spring Boot, please contact us Mauricio Salatino / Thomas Vitale via Twitter or LinkedIn.
Thanks to Spencer Gibb, Chris Bono, Marteen Mulders and Mark Fussell for reviewing the content hereof this blog post.
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.


