Cloud-Native Local Development with Testcontainers and Dapr
In this post, we will cover a set of challenges that cloud-native application developers face when building complex distributed applications and some tools that can alleviate their pain.
Mauricio Salatino
Staff Software Engineer
Developing cloud-native applications can be challenging for teams not used to managing infrastructure on cloud providers or remote environments. Adding new services to the system increases the testing complexity as the dependencies between components tend to grow and become more complex the larger the system is. In this post, we will cover a set of challenges that cloud-native application developers face when building complex distributed applications and some tools that can alleviate their pain.
Learning Kubernetes for developers can be a challenging task, as with a vanilla Kubernetes installation, teams will only be able to deploy, run, and scale their containerized workloads. A natural first step is to learn the basics of containers and how using containers will affect an overall application architecture. Following practices like 12-factor apps (https://12factor.net) you can get a long way in understanding how teams can create separate and independent services to compose complex business applications. However, your team will quickly hit the first challenge: creating secure and efficient containers for your workloads is not easy. Delegating this task to developers might be okay at first, but at scale, this process needs to be owned and managed by a specialized team that defines how containers are going to be created, optimized, and secured across the whole organization. This is the role of a platform team.
Once you have containers, you might want to run these containers on a Kubernetes cluster to validate that your applications are doing, what they were designed for, and that they play nice with other services and applications that they need to coexist with. In my experience, teams struggle with this step, as they are faced with very disparate options that can be expensive on one hand or extremely resource-intensive on the other. There are tools to alleviate this challenge such as MiniKube and kind for local development, vcluster to run smaller and isolated clusters inside real clusters, to have dedicated clusters for teams on Cloud Providers. But still, development teams are faced with the need to learn a whole new toolchain just to run, test, and in some cases develop their applications. To make things more complicated, it is common to require multiple tools to be installed in your Kubernetes clusters to enhance and extend its behavior and capabilities. If you look at the CNCF landscape (https://landscape.cncf.io) you will notice that tools can be classified roughly into three categories: infrastructure (networking, storage, security), platform tooling, and developer-facing tooling.
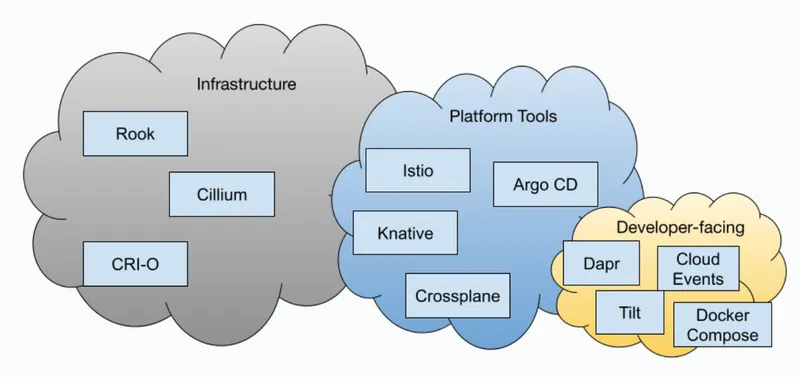
In this blog post, I want to focus on the developer-facing tools that are becoming vital to development teams and importantly the APIs that they need to build complex distributed applications.
APIs for cloud-native developers with Dapr
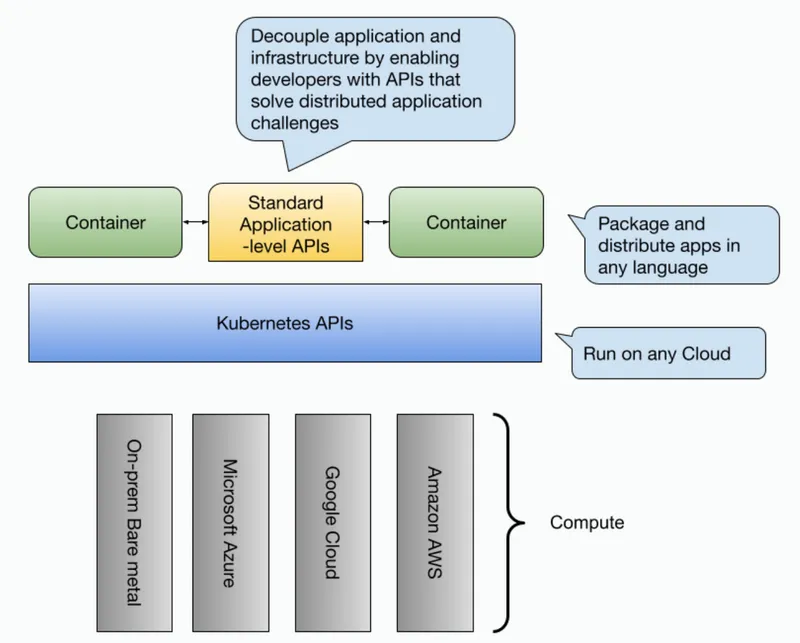
Kubernetes gave us standard APIs to deploy, run, and scale our workloads no matter where we are running our applications (cloud providers or on-prem). Containers (images) on the other hand gave us a standard way to package and distribute our applications. What about how our services interact with each other and with required infrastructure such as databases, message brokers, caches, and file systems?
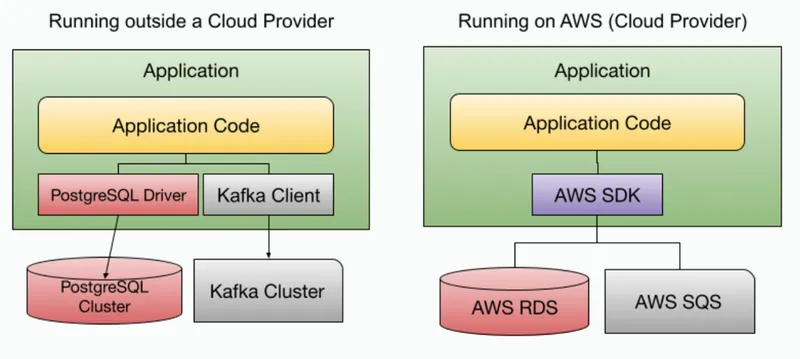
Most application development teams are forced early on to make a choice on how their services interact with the available infrastructure and with other services or third-party applications. Once these decisions are made, your containers strongly depend on the infrastructure to be available and match the application requirements (version, protocols used, vendor, etc.). Let’s use a simple example, no matter which programming language your teams are using, if they are creating an application/service that needs to store data and consume/emit messages, your application is heavily dependent on two components (a database of some sort and message broker) to be reachable not only in the production environment but also for the team to perform day to day development tasks. Let’s use an example application storing data in PostgreSQL and using Kafka to exchange messages with other applications/services.
The figure below shows the same application running outside of a cloud provider, for development and testing purposes, while on the right we can see the same application running on AWS with Amazon RDS which is compatible with PostgreSQL and AWS SQS, which unfortunately is not compatible with Kafka.
To reduce the gap between environments, it will be up to the teams to make sure that the versions of the components used for development are similar or compatible with the versions that are being used in the production environment. Once your application container includes the AWS SDKs, this application becomes bound to AWS services. Running the same application on Google Cloud or Microsoft Azure requires the application to change its internal dependencies. One thing is for sure, these application dependencies are making applications less portable and tied to the lifecycle of components that might be completely out of the application development team's control.
In this space, closer to developers, tools like Dapr (https://dapr.io) shine. By using an API-centric approach Dapr aims to enable application development teams with APIs to decouple applications from their infrastructure components. Dapr provides APIs for developers to facilitate common cloud-native / distributed application challenges. From a high-level overview, Dapr sits between your application and infrastructure components, providing applications, no matter which language they are written, with standard APIs to tackle common challenges such as storing state, emitting and consuming events, resiliency policies, etc.
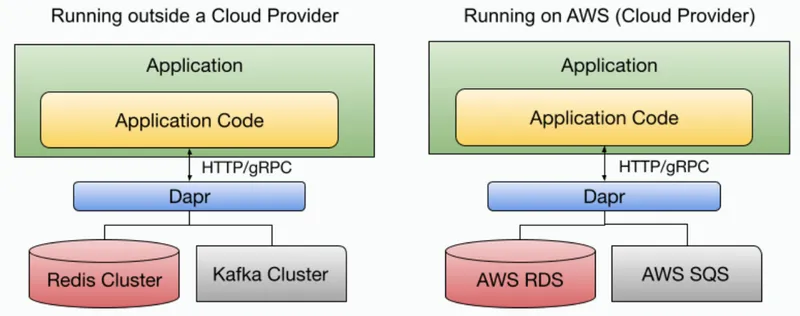
While Dapr is not bound to Kubernetes and can be run outside Kubernetes, extending Kubernetes with Dapr capabilities makes a lot of sense to provide an extra layer of portability to your applications.
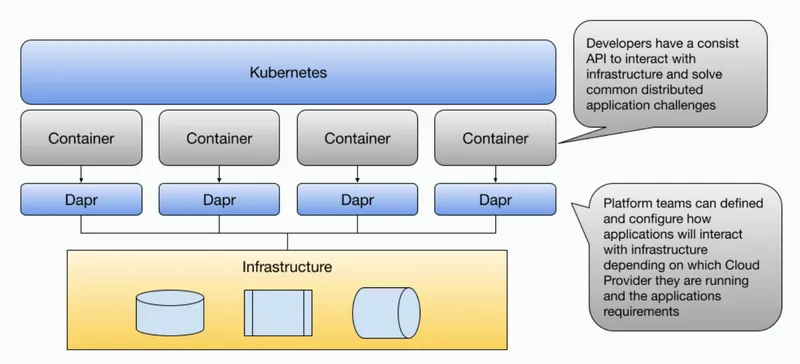
But you might be wondering already, if we don’t want all our development teams to learn about Kubernetes, we probably don’t want to also add Dapr into the mix. How can we leverage Dapr without dealing with the cognitive overload of setting up and running all these projects together?
We want to enable teams to rely on standard APIs for deploying and running their workloads (Kubernetes), standard contracts to package and distribute their services as containers (such as OCI https://opencontainers.org/ ), and also standard APIs to enable each service to connect and make use of the available infrastructure in a cloud provider/infrastructure agnostic way, but without sacrificing developer productivity.
If you are enabling your teams with Kubernetes clusters already, installing Dapr on these clusters is a natural step. If they don’t have access to Kubernetes clusters, the Dapr project provides a local development experience introducing the dapr CLI and integrations with Docker Compose. Adopting the Dapr proposed inner development loop with the dapr CLI can be okay for some teams, but disrupting for others, that might have a very polished and opinionated development inner loop in place, where adding new tools can slow them down.
Another important factor to consider is that the dapr CLI was designed to provide a language-agnostic flow, without imposing any specific programming language. While this aims to standardize how developers using different technologies interact with the Dapr APIs, developers already familiar with language-specific tools such as IDEs and CLIs might not prefer a generic flow that doesn’t fit their well-known tools and practices.
Let’s take a look at one approach that can be used to reduce the friction of adding new tools without disrupting existing development workflows.
Local development inner loops
No matter the programming language that you are using, we want to enable developers to build portable and complex distributed applications. We want these applications to run across cloud providers and even on-premises without the need to change the application internals. At the same time, we don’t want to disrupt the tools or processes that developers are already using to code their services.
Unfortunately, there are no shortcuts here, we need to look into the language and tool-specific workflows that developers are already using. We can enhance these workflows to ensure that applications built on standards can be deployed across cloud providers and integrated with the existing infrastructure.
Let’s look into two different ecosystems: Java and Go, their existing tools, and how tools Dapr can fit into their workflows.
How does this process look for Java developers?
Let’s start with Java. If you are a Java Developer you are most likely using an IDE such as IntelliJ, Eclipse, or Netbeans and you might have some specific plugins to perform certain tasks, such as start your application, debug it, etc. For building your application and to handle dependencies you might be using Maven or Gradle, consuming libraries and artifact repositories such as Maven Central. If you are building services (or microservices) it is most likely that you are using Spring Boot or Quarkus, as these projects follow the 12-factor principles and provide developers with a very mature programming model full of extensions and capabilities.
Nowadays, frameworks like Spring Boot and Quarkus provide integrations to create and distribute container images and even create Kubernetes manifests. If your Java developers are not creating containers or deploying straight to Kubernetes, they tend to stick to the Spring Boot developer workflow which might be using their IDE bindings to run commands such as mvn spring-boot:run or mvn test.
How does this process look for Go developers?
If you are using Go, you are probably using VScode or no IDE, you might have a Makefile to build your application for different platforms and you are most likely to be using Go Modules as your dependency management tool (consuming dependencies from tons of different GitHub repositories). While there are Go frameworks aimed to facilitate the creation and development of services (or microservices) it is most likely that you are using something like Go CHI to expose HTTP endpoints, the gRPC SDK, or frameworks like Fiber. While in the Java community, most best practices are encoded into frameworks, in the Go community conventions are documented and evolved over time. If you are aiming to deploy your Go application on Kubernetes you can check specific guides such as https://github.com/ardanlabs/service/tree/master and https://github.com/golang-standards/project-layout/tree/master/cmd that describe project layouts and how to manage the complexity of Go projects when teams are building a set of related services. Tools like ko-build (originally created by Google) were designed not only to make the creation of containers transparent to developers but also to enable developers with a very opinionated and fast developer workflow to quickly change and deploy new versions of your Go containers to a Kubernetes Cluster. If your Go developers are not deploying their services to Kubernetes clusters, they tend to just stick to their Go workload, using go run and go test targets.
Wiring cloud-native tools to our existing flows with Testcontainers
Let’s tap into our Java and Go developers' workflows to see how we can expand the capabilities that they can use without disrupting their day-to-day work. Testcontainers is a tool that allows teams to define which containers need to be run beside your applications for development and testing purposes. Testcontainers was created in the Java community first so it is well integrated with frameworks like Spring Boot and Quarkus. Today Testcontainers provide support to multiple languages including Go, Python, .Net, Rust, and Ruby, among others. A simple example to demonstrate the value of Testcontainers is to imagine the scenario that we described in the intro; you have a simple application that depends on PostgreSQL and Kafka. With Testcontainers, you can provision both Kafka and Redis when you are starting the application from your IDE or when running tests. The main difference with using tools like Docker Compose is that Testcontainers understand the lifecycle of your applications. This allows developers to define when and how these containers (PostgreSQL and Kafka for example) need to be created and when they need to be cleaned up. Testcontainers also support being read into your Docker Compose files (Testcontainers Compose) to avoid having duplicate definitions of which containers are required by the application.
Summing up, Java developers only need two things to use Testcontainers: Add the Testcontainers dependency to their Spring Boot/Quarkus project Provide the definition of which containers and which configurations need to be used to start them
Java developers then, can start their applications for development purposes and rely that all the required infrastructure will be available and wired up for the application to use.
Go developers, on the other hand, have a different flow, where they will use go run to start up their apps, there is no development mode like in Spring Boot or Quarkus, the app just runs. It is quite common for Go developers to have a Docker Compose file that they will manually run before starting the application, and they will need to set the URLs and credentials for the application to connect to these containers. An alternative approach in Go can be the use “Go Labels” and init functions to run code under specific situations, as described in this blog post showing how Fiber, a Go framework, and Testcontainers can be easily integrated: https://www.atomicjar.com/2023/08/local-development-of-go-applications-with-testcontainers/
Now running your application with a specific tag (go run -tags dev .) will automatically enable Testcontainers to manage the lifecycle of the containers that your application needs to run locally.
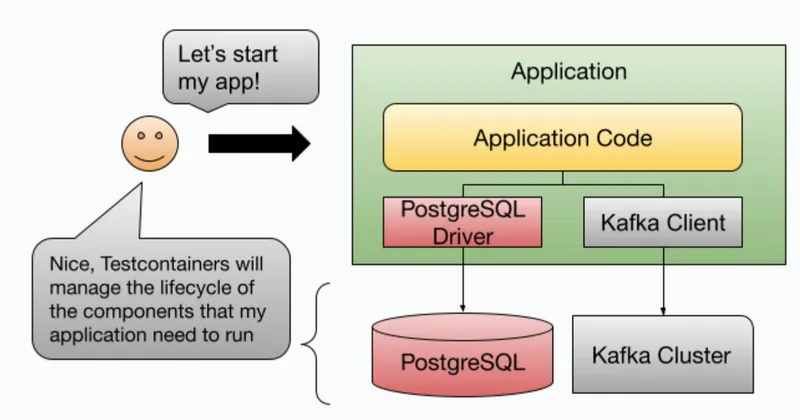
While this is a great improvement for developers, we are back at square one, our application still heavily depends on the infrastructure components, their versions, and their lifecycle.
How would Dapr fit into this approach? One of the amazing things about running Dapr on Kubernetes is that Dapr gets automatically injected into your application’s Pod, meaning that your application will have access to the Dapr APIs in their local Pod network (localhost).
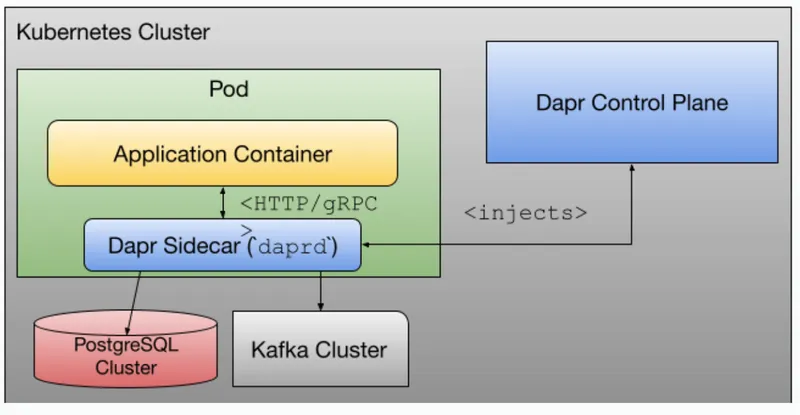
When running outside of Kubernetes, there is no automatic injection, the developer would be in charge of bootstrapping the Dapr APIs, which would totally defeat the purpose of making their life easier. This is where Testcontainers can really help.
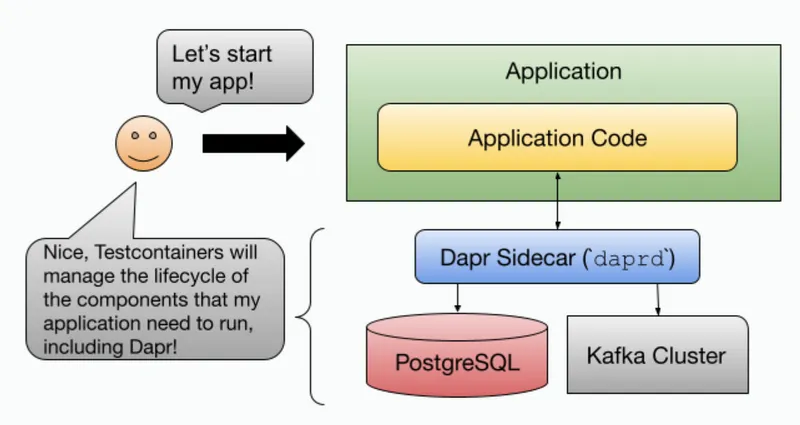
Why is this important? There are several reasons, let’s look at some of them: The application code doesn’t need to have any dependencies from Kafka or PostgreSQL Application developers can use the Dapr APIs to build the application logic without worrying about which components are providing the implementation The infrastructure (PostgreSQL instance and Kafka Cluster) can evolve (be patched, upgraded, or replaced by a different component) without the need to change the application code When running the application into different environments, a platform team can configure Dapr to connect to existing infrastructure without the need to change the application
We have made our applications portable across cloud providers and environments, by relying on standard APIs provided by Dapr and by removing their dependencies with infrastructure components.
Sum Up: From Development to Production
Both, having standard APIs that can decouple our application code from infrastructure and having the right testing approach to minimize risk when moving services from development to production environments directly contribute to the delivery speed of our applications.
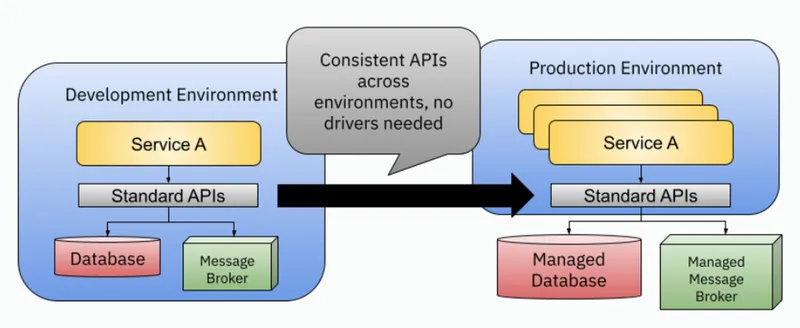
Reduced friction between development environments and production environments can be achieved by understanding which tools, services, and APIs developers need when developing their applications and enabling platform teams to wire and configure the infrastructure without the need to change application code.
In this blog post, we have looked into two specific tools, Dapr and Testcontainers. Both of these projects aim to support developers working on cloud-native applications without imposing any programming language or tooling that might conflict with their existing workflows. By combining these two tools together, development teams can focus on adding business value, while a platform team can focus on providing developers the configurations required to run their applications across environments, including their local workstation.
If you are interested in these two projects, you check the following webinar. You can also check the step-by-step tutorial located in the following GitHub repository.
If you have questions about Dapr, you can join our discord server: https://bit.ly/dapr-discord If you are interested to learn more about Testcontainers you can join their community slack: https://slack.testcontainers.com
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.


