Tuning Dapr Scheduler for Production
Learn different ways to schedule tasks in Dapr through Cron binding, Jobs API, actors, and workflows. Then, see how to prepare the Dapr Scheduler for production with the right configurations for durability, security, and scale.
Bilgin Ibryam
Principal Product Manager
Scheduling tasks such as batch processing, notifications, or periodic maintenance is a common need in distributed applications. While Dapr has long supported basic scheduling via cron bindings and actor reminders, production-grade use cases require stronger durability, reliability, and scale.
With the introduction of the Scheduler service and the Jobs API, Dapr now offers a centralized, highly available solution for durable and scalable time-based task execution. This article explores the available scheduling options in Dapr, highlights their trade-offs, and provides production-ready guidance for configuring the new Scheduler service to ensure reliable task execution across your applications.
Understanding Dapr's Task Scheduling Options
Dapr provides several ways to schedule tasks, each with different tradeoffs in reliability, scalability, and developer abstractions. Let’s briefly look at the available options, what they’re good for, and why you might want to use something more robust for production workloads.
Cron Binding
Cron binding is the simplest and most accessible way to schedule a task in Dapr. It’s defined declaratively in a component spec, using a familiar cron expression to call any app endpoint, regardless of the language or framework used. This language-agnostic, configuration-driven model is its main strength. However, developers should be cautious:
- No durability – scheduled events can be lost during restarts or downtime.
- No coordination – each replica runs the schedule independently, causing duplicate triggers.
In practice, cron binding works best for simple, best-effort scenarios because it is stateless and not clustered. When the target app is scaled to multiple replicas, the schedule will fire on every instance. Here are important tips to keep in mind:
- Use Dapr resiliency policies for retries to handle transient failures—for example, configure retries and increase timeout durations to account for delayed responses.
- Scope the component so it triggers only the desired app. Avoid triggering unintended apps by explicitly setting the target app ID. If you're using Diagrid Conductor, its advisors can detect and report unscoped components automatically.
For production-critical jobs, the Jobs API offers a more durable, scalable, and fault-tolerant alternative.
Jobs API
The Jobs API was designed not only to address the limitations of the cron binding, but also to offer a fully durable and scalable scheduling capability as a native API in Dapr.
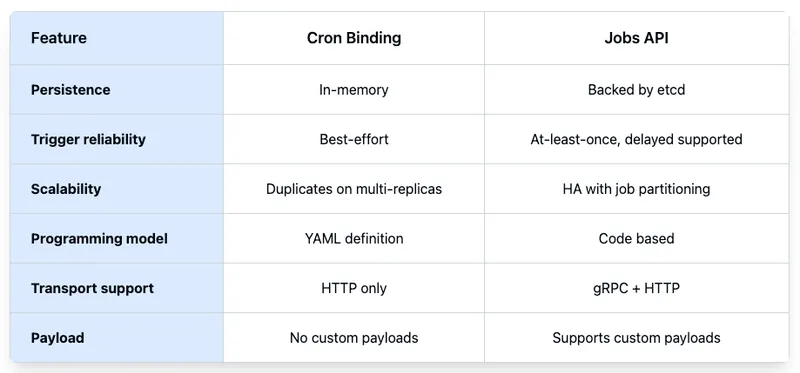
Cron Binding and Jobs API Differences
Introduced in Dapr 1.14, the Jobs API provides a first-class interface for managing and executing background tasks with strong reliability guarantees.
It improves on the cron binding in several critical ways:
- Durability: Jobs persist across applications and Dapr restarts. They are stored not in the sidecar but in a dedicated control plane component backed by an embedded etcd store designed for high availability and reliability.
- Payload support: Custom payloads can be attached to each job at creation time. These payloads are delivered to the application when the job is due, allowing context-aware job execution.
- At-least-once delivery: Ensures jobs are retried and executed even in the presence of failures.
- Scalability: Designed to handle millions of jobs without degrading performance.
Behind the API is the Scheduler service—a centralized Dapr control plane component built for durability and scale. It uses an embedded etcd store for strongly consistent, persistent job storage without external dependencies. A distributed cron library assigns job ownership across Scheduler instances for horizontal scaling without coordination overhead.
At trigger time, the Scheduler streams jobs to all connected Dapr sidecars. Each sidecar watches every Scheduler, and jobs are round-robined to healthy app replicas. If delivery fails, Dapr's resiliency policies automatically retry until the job is acknowledged. This flow ensures reliable, scalable job execution from storage to application logic. For deeper insights, see the blog post: Introducing the new Dapr Jobs API and Scheduler Service.
Actor Timers and Reminders
Unlike the Jobs API or cron binding, which are general-purpose, language-agnostic ways to schedule endpoint calls, actor timers and reminders are tied to the Dapr Actor programming model. Actors are a stateful, single-threaded abstraction for building concurrent, distributed applications. While their primary use case isn't scheduling, they often need to trigger time-based operations.
Dapr supports two mechanisms:
- Timers: Stateless, in-memory triggers that run on a fixed interval. Timers are ideal for short-lived, lightweight recurring operations that don't require persistence, such as internal retries, polling, or periodic cleanup logic that can be safely dropped if the actor is deactivated.
- Reminders: Durable triggers persisted with the actor’s state. Reminders are suited for durable, critical tasks that must survive crashes and restarts—such as subscription expirations, scheduled state transitions, or long-running coordination tasks. Since Dapr v1.15, reminders are stored in the Scheduler service, improving their reliability and scalability.
Timers and reminders can only invoke methods on the actor that scheduled them, making them useful for actor-based workflows, but not suitable for general-purpose or cross-service scheduling.
Workflow Timers and Delays
Similar to actors, Dapr Workflows is a programming model with its own built-in scheduling semantics. It allows you to express time-based logic as part of workflow definitions.
Workflow timers and delays let workflows pause, resume, or trigger steps at future times. These durable timers support arbitrary durations or fixed points in time, enabling scheduled state transitions.
For example, a subscription workflow could wait 30 days before transitioning from a free trial to billing. Under the hood, Dapr Workflows also use actor reminders to ensure execution continues across restarts or failures. Since Dapr v1.15, those reminders have also been stored in the centralized Scheduler service.
Hardening Dapr Scheduler for Production
The Scheduler service underpins several core Dapr features: the Jobs API, actor reminders, and workflow execution. Its reliability directly affects the correctness and availability of scheduled operations system-wide.
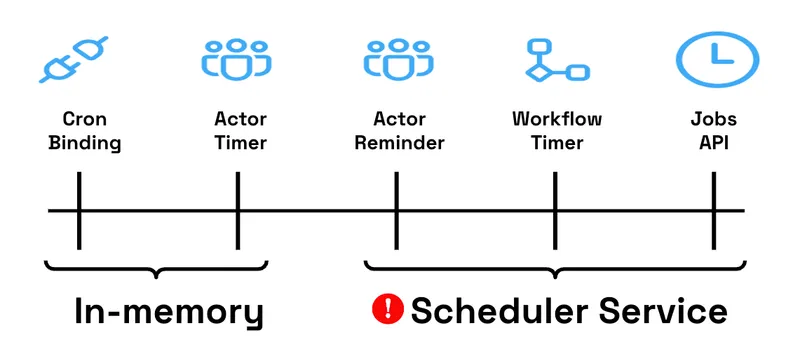
Dapr capabilities backed by the Scheduler Service
As a stateful service, it requires deliberate configuration for production deployments.
Ensuring Reliability and Security
In production environments, you need to configure the Scheduler service to run reliably and securely. This means setting up proper availability, security configurations, and protection from unexpected termination.
Scheduler High Availability
In Kubernetes, the Scheduler service is always deployed in high availability (HA) mode by default. It runs as a three-node embedded etcd cluster to ensure durability and resilience against pod or node failures.
In production, it's best practice to run all Dapr control plane components in HA mode:
global.ha.enabled=trueHA configuration ensures that your scheduled jobs, actor reminders, and workflow timers remain available and consistent, even during failures.
Running Scheduler Without Root Privileges
Like all Dapr control plane components, the Scheduler should run as a non-root user to minimize security risks in production.
dapr_scheduler.runAsNonRoot=trueThis follows the principle of least privilege and helps prevent container breakout attacks or privilege escalation. For enterprise environments with strict security requirements, this configuration is essential to passing security audits and maintaining compliance.
Protecting Scheduler from Eviction
During node pressure, Kubernetes may evict pods based on priority. Scheduler, like other Dapr control plane services, should be assigned a high priority to avoid eviction during node pressure and potentially disrupting all scheduled operations across your system.
global.priorityClassName=system-cluster-criticalBy assigning a system-critical priority, you ensure the Scheduler pods will only be evicted after your application workloads, preserving scheduling integrity during resource constraints.
Keeping an Eye on Scheduler
Configuring for availability is just the first step; actively monitoring to ensure that the configuration is working as expected is key. Tracking Scheduler availability, resource consumption, and health status helps you catch potential issues before they impact your scheduled jobs, actors, or workflows.
Diagrid Conductor includes built-in alerts for all Dapr control plane components, including the Scheduler service. These alerts provide immediate notification when issues arise, such as pod failures, resource constraints, or configuration problems, without requiring manual setup of complex monitoring rules.
Right-Sizing Scheduler Resources
Beyond reliability and security configurations, the Scheduler service needs proper infrastructure resources to function effectively at scale. This includes appropriate compute resources and storage.
Setting Compute Resources
Resource requirements for the Scheduler service depend heavily on workload characteristics such as the number of jobs, actor reminders, and the size of stored payloads. There's no one-size-fits-all configuration. Start with a baseline and adjust based on observed usage:
resources:
requests:
cpu: 200m
memory: 512Mi
limits:
cpu: 1000mIn production, monitor actual CPU and memory usage to tune these values. Consider omitting memory limits to reduce the risk of OOMKilled errors.
For systems with thousands of jobs or reminders, you may need to increase the memory allocation. The Scheduler service maintains in-memory data structures for efficient job triggering, so memory becomes more important as your job count increases.
Allocating Sufficient Storage for Scheduler Workloads
Allocating Sufficient Storage
Scheduler uses embedded etcd for storing jobs and reminders. Storage needs vary based on job volume, payload size, and data retention. The default 1GB storage allocation is insufficient for most production workloads, leading to etcd exhaustion errors.
dapr_scheduler.cluster.storageSize=16Gi
dapr_scheduler.etcdSpaceQuota=16GiFor most production environments, start with 16GB and monitor usage. This space is used both for current jobs and historical data required by etcd for its consistency protocols. When the storage is exhausted, you'll see errors like:
Selecting the Right Storage Class
Scheduler's embedded etcd is write-heavy and latency-sensitive. Avoid default storage classes backed by slow or burstable disks.
dapr_scheduler.cluster.storageClassName=scheduler-ssdUsing an SSD-backed storage class with appropriate IOPS for your cloud provider ensures optimal performance and reliability for the Scheduler's embedded etcd database.
Regular Scheduler Backups
While the HA configuration protects against individual failures, catastrophic failures or accidental deletions require proper backup strategies.
Implement etcd snapshot backups as an automated CronJob to protect against cluster-wide failures or human error, ensuring you can recover your scheduling state if needed.
Continuous Dapr Best Practices Monitoring
Ensuring your Dapr installation operates correctly is not a one-time activity—it requires continuous, proactive management. As Dapr evolves with new versions and more applications move to production, manually verifying best practices across clusters becomes increasingly time-consuming and error-prone.
Diagrid Conductor continuously analyzes your full Dapr environment—including the Scheduler—against over 50 production best practices across security, reliability, performance, and observability. Its Advisor feature automatically detects misconfigurations before they impact your applications and provides clear remediation steps.
Start your free Conductor trial, deploy the Conductor agent, and receive a full production readiness report by email within minutes. This simple action can significantly improve your security posture and prevent downtime caused by misconfigurations.
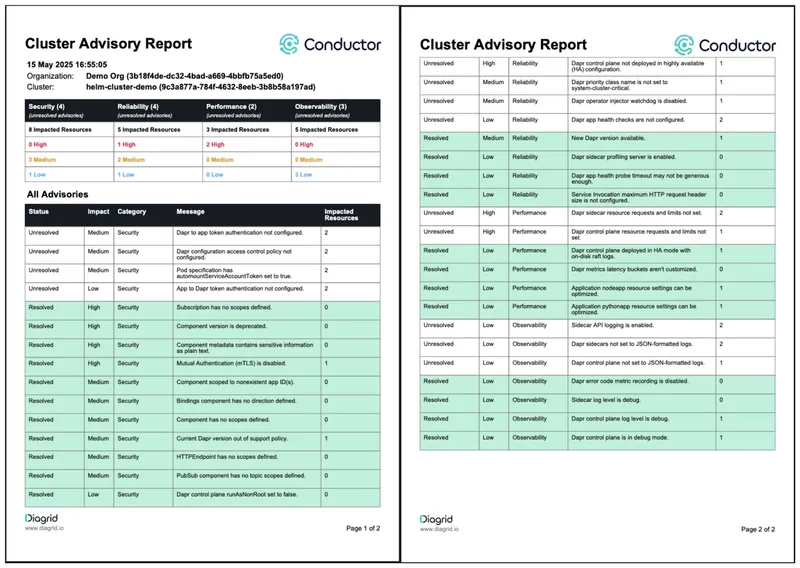
Diagrid Conductor advisor report by email
Keep the agent running for 15 days and receive a second report with detailed performance tuning and cost optimization recommendations based on real-world system load. This analysis examines Dapr sidecar and control plane resource usage, offering precise CPU and memory sizing guidance. Customers like ZEISS have achieved up to 80% reduction in memory usage by following these recommendations—read the case study to learn more.
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.


