The Evolution of Cloud Computing: From Raw Infrastructure to the Serverless Application Cloud
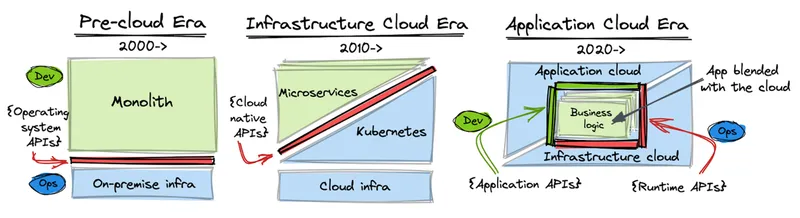
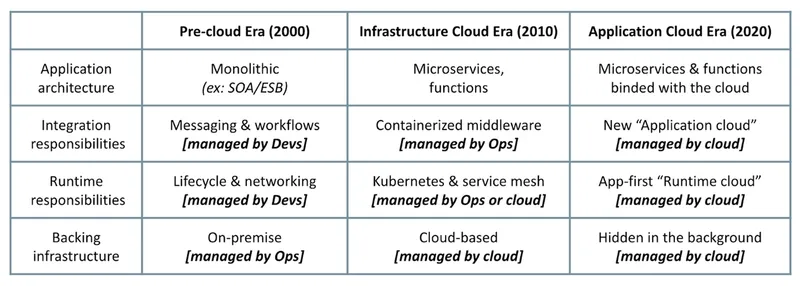
In this post, we are going to describe rough evolutionary stages characterized by major trends in the infrastructure and application architectures and responsibilities.
Bilgin Ibryam
Principal Product Manager
Cloud computing is on the path to commoditize the full software stack, except for the business logic. It started from raw infrastructure, but it is moving higher up the stack to the application layer. The evolution of the cloud changes the way we implement, and operate applications too. Once monolithic applications responsible for all aspects of a distributed application, transitioned to containerized microservices and functions orchestrated by the platform, today are fully blending with the cloud services and delegating their control flow to the cloud services.
Cloud computing commoditizing the application stack
In this post, we are going to describe rough evolutionary stages characterized by major trends in the infrastructure and application architectures and responsibilities. We will use AWS for demonstration purposes, but the same trends can be observed with other cloud services. We will look at how applications and the infrastructure interact, over what kind of APIs, and how application responsibilities shift towards the infrastructure before getting commoditized by the cloud services.
The pre-cloud era
This is the time of monolithic applications and on-premise data centers and early-cloud services. Today, such a set-up is considered legacy, and we will describe it here mainly as a starting point of the distributed application evolution. In this architecture, all distributed responsibilities are delivered from within the application, and the infrastructure is treated as dull and static as possible.
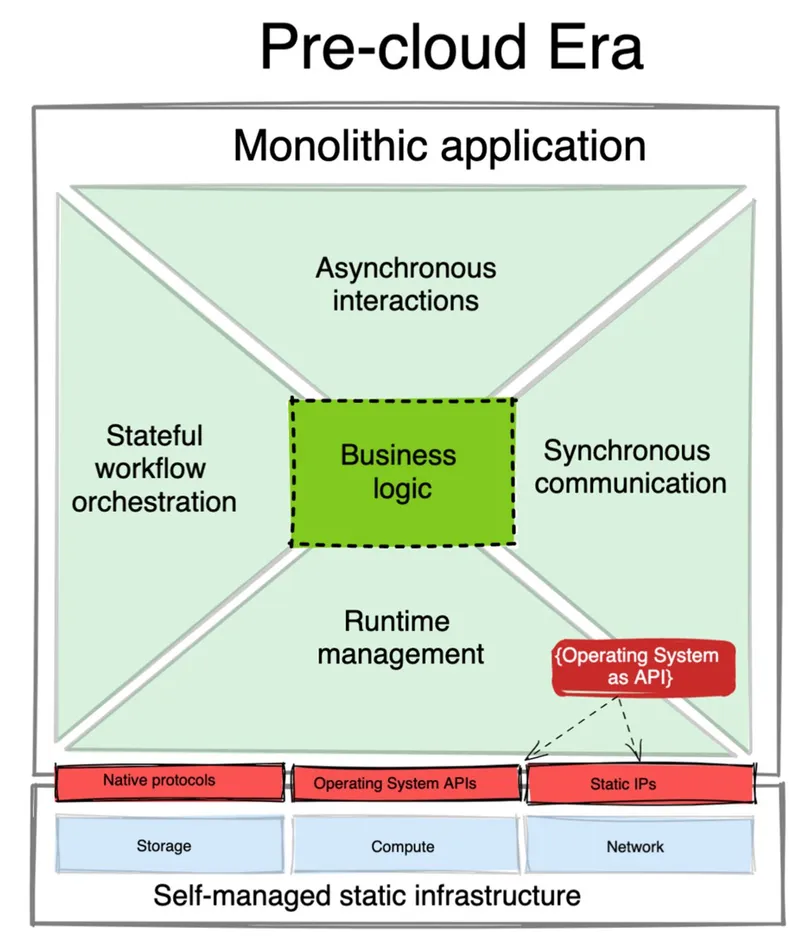
The pre-cloud era of monolithic applications and static infrastructure
Static infrastructure
From the infrastructure point of view, this is the time before Kubernetes, and the early days of AWS EC2 adoption. The main characteristics of this era is the static nature of the infrastructure composed of large virtual machines. These units of infrastructure would host multiple applications, and even some stateful components such as databases, message brokers, and content stores.
Monolithic applications
On the application side, the best representative of this architecture is the SOA and Enterprise Service Bus as the implementation. These applications would have a large monolithic deployment capable of satisfying many needs such as:
- Runtime and deployment: new releases typically packed as libraries, and scheduled on pre-selected nodes, with manual rollback.
- Synchronous communication: ability to do service discovery, load balancing, retries, circuit breaking, etc. Not so much traffic shifting and canary release, as new releases would be done in a single go for the whole application, and have in-memory interactions.
- Asynchronous interactions: having a large collection of connectors, with ability to transform, filter, and route messages and events.
- Stateful workflows: the main characteristic of the monolithic architecture is the shared state which simplified performing stateful orchestration, idempotence, caching, scheduled tasks, etc.
Because the infrastructure provided only raw compute, storage, and networking, the application stack would be responsible for delivering most of the business capabilities, taking care of non-functional requirements, and the deployment process.
The operating system as an API
In this era, there are no common application and infrastructure abstractions, nor common technologies and practices shared by developer and operations teams. These siloed teams would use the operating system, fixed IPs, and the VMs as demarcation of the application stack. The operations team would be responsible for provisioning of the VMs, and ensuring there is plenty of extra capacity for future application growth. The developers would be responsible for implementing all aspects of the distributed application that runs on that infrastructure. Due to the lack of a universal packaging format, and runtime APIs for the deployment and placement, every application would be released as a unique collection of libraries with instructions written in a human-readable wiki, rather than a machine executable file that is reproducible. The APIs that the application and the infrastructure interact with are the operating system APIs, in the form of starting a process, killing it, fixed machine IP addresses, rather than application abstractions. In this infrastructure-first era, the application is a second-class citizen, and the developers had to adapt and conform the application to the shape and interfaces of the infrastructure.
The infrastructure-centric cloud era
This is the time of transition to microservices, containers, Kubernetes, and mass cloud migration. It is characterized by rearchitecting applications into microservices, and shifting application lifecycle and networking responsibilities from the application layer to Kubernetes and complementary technologies.
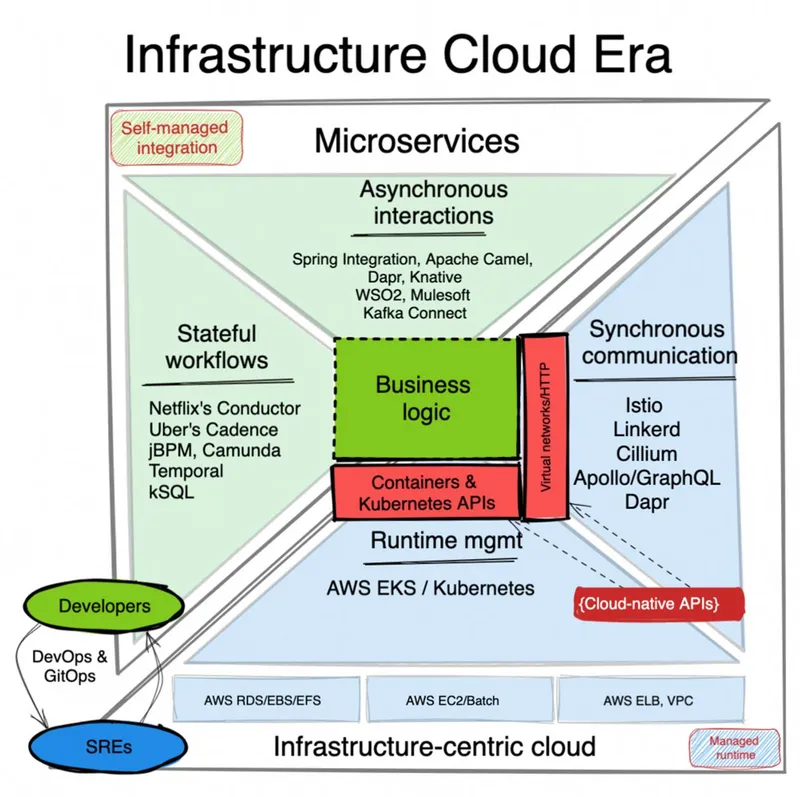
The infrastructure cloud era of Microservices and Kubernetes
The cloud(-native) infrastructure
There are two major infrastructure shifts in this era. First is the adoption of cloud infrastructure and migration to EC2s, ELBs, RDS, etc. These cloud services offer the same coarse infrastructure units and APIs as the on-premise infrastructure but shift the responsibility of the management, monitoring, scalability, and reliability, from the in-house operations team to the cloud providers. The second major trend is the advent of containers and Kubernetes which lead to a managed application lifecycle. Containers brought a universal packaging, isolation, and runtime application format. And Kubernetes introduced abstractions and declarative APIs for mass orchestration of applications taking care of the lifecycle and networking concerns. With these two leaps, the raw infrastructure migrated to the cloud, and application lifecycle responsibilities shifted to the infrastructure remit. Let’s see how that impacted the application layer.
Microservices architecture
With monolithic applications breaking down into independent deployments, initial microservices contained too-much infrastructure within them. With containers, Kubernetes and Service Mesh technologies, these responsibilities moved out of the application stack. Lifecycle and deployment concerns such as health checks, scaling, configuration, became part of the infrastructure layer, whether that is Kubernetes Pods, AWS Beanstalk, or Heroku Dynos. Networking concerns moved out of the application layer too. Service discovery, load balancing, mTLS, network resiliency started shifting first into sidecars such as Envoy, then to a shared node agent such as Istio’s Ztunnel, and some features such as observability and mTLS even further down into Linux kernel through eBPF and Cilium. This left event-driven integrations and workflow responsibilities that impact the application control flow and business logic still within the application and the reach of developers, for now. But rather than having them embedded within a monolithic application, they would be deployed as standalone middleware, some focused around eventing (ex: Kafka ecosystem), some stateful workflows (Camunda), and other libraries offering stateless integration capabilities (like Apache Camel).
Kubernetes as an API
With raw infrastructure commoditized, cloud providers shifted their focus up to the application layer. Containers and Kubernetes API became common knowledge for application packaging and resource lifecycle management. This is the first time that there is a commonly accepted application-first API that controls the lifecycle and networking aspects of an application and not the whole VM. Having packed the application into a container image, with ports and health checks, defined, the application can be handed to the operations team to run it at scale as a black box, without any manual interventions. On the networking side, HTTP and REST, became the norm for synchronous application interactions, and Service Mesh implementations used for controlling that traffic by shifting, observability, mTLS, and resiliency features. This is the time when developers and operations teams started using common tools and practices such as GitOps, DevOps which led to better collaboration between them overall. That meant, there is a common API for the application lifecycle and networking aspects, which set the scene for the next stage of commoditizing what’s left from the application layer.
The application-centric cloud era
Today, the application lifecycle and networking are managed mostly transparently to the application. Other than one or two health endpoints, developers do not have to code anything within the application for a cloud runtime to run, scale, and route traffic to the application. These “Runtime Cloud” services operate transparently to the application, using container-based abstractions for the lifecycle aspects, and HTTP/TCP traffic routing techniques. But that is not true for integration aspects (event-based or stateful workflows) of distributed applications that directly interact with application control flows and the business logic. What I call here “Application Cloud” is the collection of cloud services that have distinct APIs and interact with an application over its purpose-built endpoints.
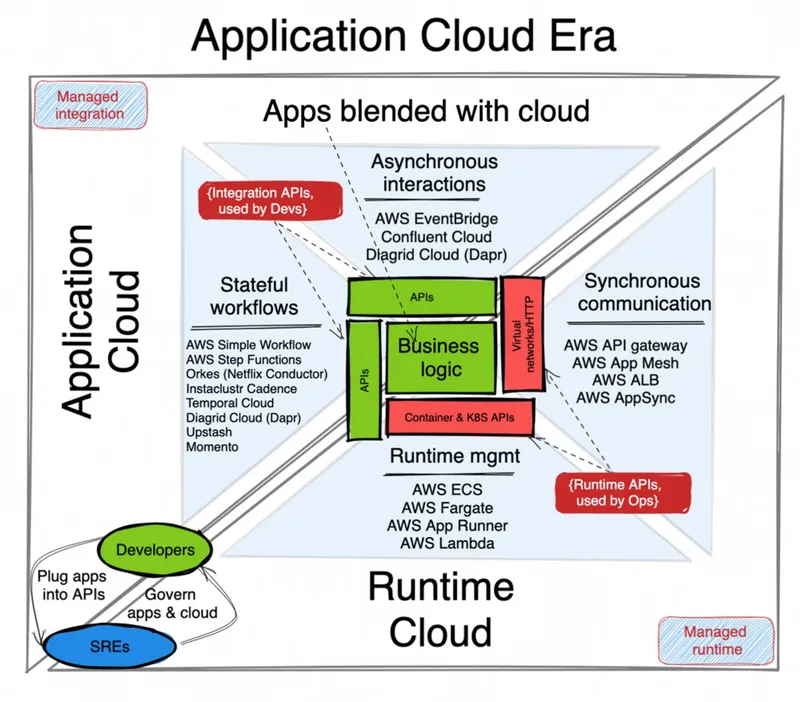
Applications blended with runtime and integration cloud services
In this model, the application code whether it is microservices or functions, is plugged into the cloud at runtime and blends with it. In this architecture, part of the application control flow runs within the application code, but part of it runs within the cloud services.
Application-first infrastructure
In this evolution of the cloud just started, the raw infrastructure cloud services (such as AWS EC2s) are pushed in the background and become transparent to the developers. There is a new serverless infrastructure cloud, that operates at the granularity of an application rather than of a VM (such as AWS App Runner) which is responsible for the application runtime, scaling, configuration and networking. The infrastructure cloud transforms into application-centric serverless runtime and networking.
The more interesting aspect of this era is the rise of cloud services that blend with the application control flows. These are integration services for event-driven and stateful workflow orchestration that interact with the application directly over the application endpoints. These cloud services can be provisioned and configured explicitly, or dynamically created on demand from a DSL within the application code. Think of AWS Step Functions, Google Cloud Workflows, or Temporal Cloud workflow orchestrating the sequence of operations to be executed on your application. Think of AWS Event Bridge that delivers filtered, transformed events to your application, or Google’s EventArc. Or a serverless Dapr service that binds 3rd-party APIs, cron-based triggers, and other applications with your application. These new “Application Cloud” services bind with the application at a deeper level than a serverless runtime service responsible for the application lifecycle only.
Cloud-bound applications
The “Application Cloud” doesn’t dictate whether your application is based on microservices, functions, or something else. In this model, part of the application integration and control logic is offloaded into the cloud and consumed as a service. This is a form of consuming the complex and repetitive specialized developer constructs through clear-cut APIs and guaranteed SLAs rather than implementing or importing them within the application. These constructs can be a connector service invoking a method on the application, it can be a stateful orchestration service calling application endpoints to commit a business transaction or invoking a compensating endpoint in the failure cases. It can be as simple as a distributed lock endpoint, cron-based trigger, or configuration update notification. By consuming these primitives as a serverless service, the application developers can concentrate on implementing the unique business logic, and operations teams on governing and controlling the best-of-breed service implementations.
Open source as the source of de facto APIs
In order for the “Application Cloud” to bind with the application in a way that can be replaced with other services, it needs a clear-cut API that can be invoked by the application or the other way around. Ideally, this API should be ubiquitous, polyglot, and cloud-agnostic, the same way containers and Kubernetes abstract the infrastructure and the network. Such APIs need to be widely adopted and be a de facto standard in their respective fields, the same way containers are for packaging and resource isolation and Kubernetes for resource orchestration. Today, one proven way for creating such de facto API standards is through the open source development model, combined with a transparent governance model of a neutral software foundation. Some successful examples of these APIs are projects such as Open Tracing, Prometheus for metrics, Kafka for event logs, Dapr for integration, etc. There are also examples of industry standards that came not from non-open source and open governance backgrounds too, such as GraphQL for data querying, AWS S3 for objects store and others. These are all examples of de facto API standards used in applications, and eventually becoming available as a cloud service on their own.
Summary
In this post we looked at a few trends that happened simultaneously and enforced each other. The infrastructure moved from on-premise to the cloud. The application architecture on top, shifted from monolithic to microservices and functions. While these changes were happening, containers and Kubernetes introduced application-specific lifecycle abstractions and shifted the infrastructure focus to the application layer.
Applications blending with runtime and integration cloud services
With all major cloud providers shifting focus to application-centric runtime and integration services, the biggest transition is yet to happen. There are a growing number of application-first serverless cloud services for eventing and stateful orchestration. These are a new breed of services blending with the application to deliver some developer constructs in a reliable and secure way. These application services will change the way we look at the application architecture from a single deployment unit, into one that is blended with the cloud. Building of this new breed of cloud services forming the new “Application Cloud” just started. If you would like to learn more how Diagrid can help your organization utilize the Dapr-based application cloud, talk to us or follow us on Twitter for future updates.


