Top Three Use Cases for Dapr and Kubernetes
In this post, we'll explore how Dapr and Kubernetes complement each other.
Bilgin Ibryam
Principal Product Manager
Kubernetes has turned into the de-facto standard for operating distributed applications whether they are on-cluster, off-cluster, or multi-cluster. But Kubernetes is not offering many benefits to developers implementing such applications, nor the large majority of other CNCF projects. There are exceptions and new CNCF projects such as Dapr are boosting developers' productivity when implementing distributed applications. In this post, we will explore the top three use cases demonstrating Kubernetes expansion into new operational areas and why Dapr is the best-suited Kubernetes companion for developers.
Technology proliferation hinders productivity
If we look at most IT initiatives, at a high level, they fall into one of these categories: they are for increasing revenue, decreasing cost, or mitigating risk. In your organization, you may have variations of it such as increasing customer satisfaction, reducing customer churn, etc but roughly they fall in the same buckets. There are multiple ways to achieve these goals, here I've picked a few as examples, but these will be in a different order for your organization.
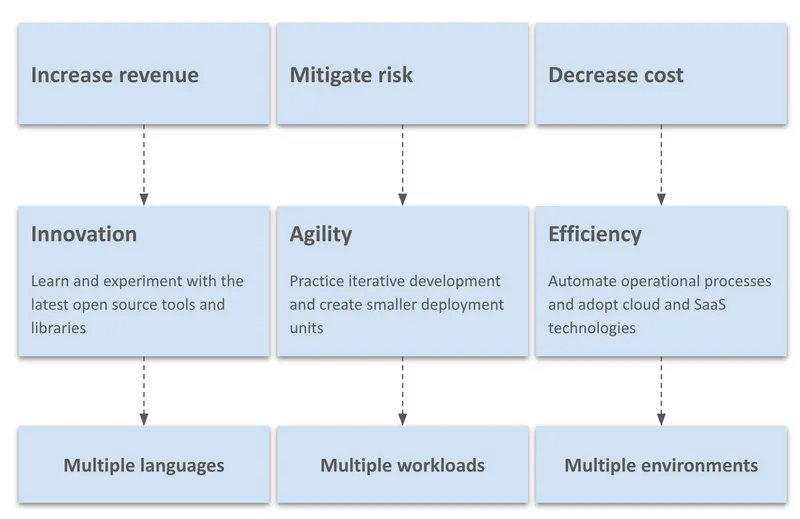
Business goals and side effects
You may decide to increase revenue through new innovative services, by using some new cool open source ML technology. You may mitigate compliance risk by updating your software on time, through iterative development practices, and smaller development units such as microservices. Become more cost-effective, not through sacking people, but through automation, adopting cloud and SaaS rather than doing everything in-house. But there are always consequences. You realize the most popular language for ML is Python, Javascript is the best language for web development, Java is for desktop, Swift for mobile, C++ for IoT apps, etc… and you end with multiple languages within your organization. Then you realize you have to operate microservices, functions, monoliths, and many other apps in between. And you have to do this on-premise and on one or multiple clouds. Looking at an organizational level, all of these lead to technology proliferation in multiple dimensions that are happening at the same time.
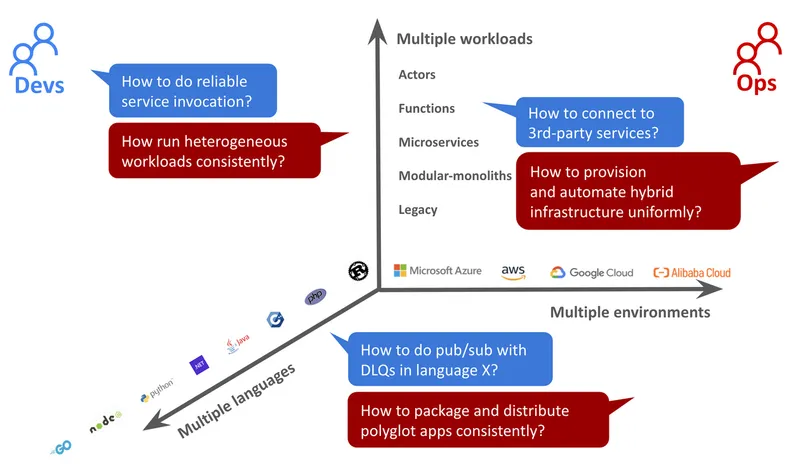
Technology proliferation impact on Dev and Ops teams
This proliferation impacts different teams at different levels. You may have your data science team using Python only, but the platform engineering team may have to provide tools for building and packaging for multiple teams using different languages. You may have teams creating greenfield 12-factor applications, but Ops teams may have to look also after monolithic applications, functions with ever-increasing numbers of instances. Your infra teams may have to create automation for provisioning on multiple clouds and on-premise deployments.
While the challenges of platform and Ops teams are around consistency and uniformity across many teams, the challenges of development teams are about productivity within their team. Very often, there are silos of developer teams that use certain languages such as Java, and .Net which are better suited for creating distributed applications, and applications that can connect to various SaaS endpoints. Whereas other teams using different languages are isolated and cannot benefit from the rich ecosystem of cloud native technologies. These teams cannot reuse the same tools and patterns for solving common problems.
What is the answer to these challenges caused by technology proliferation? One answer is in becoming cloud native, the way it is defined by CNCF and the growing ecosystem of projects there.
Developer expectations remain unmet
As a former developer, I decided to check which CNCF projects help developers with writing code and implementing cloud native applications. I've plotted roughly the SDLC phases and put them on all the graduated CNCF projects and the trend was clear. There are not any graduate projects that can help with the earlier phases of software development. I've added the incubating projects, and the trend of focusing on operating and observing applications became even stronger.
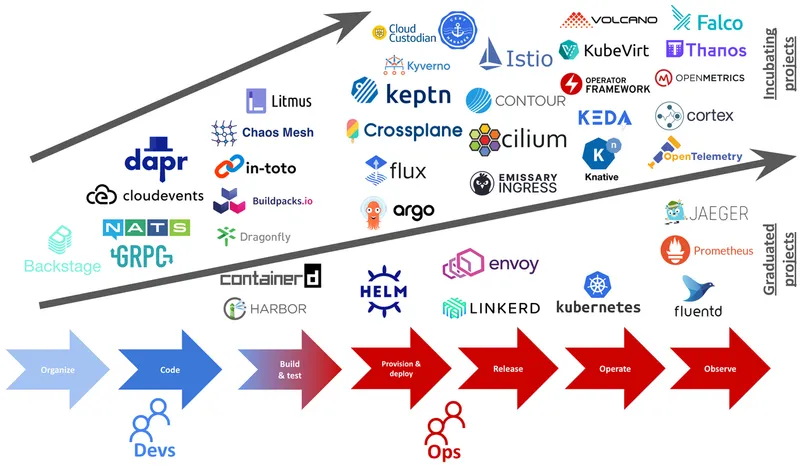
CNCF projects and their focus area in software development life cycle
This diagram has drawbacks and it doesn't represent all the changes in the ecosystem fully. For example, there are some projects focused on runtime, but help developers too. For example observability tools almost always provide client libraries. Knative serving provides autoscaling and blue-green releasing functionality for operating software, but Knative eventing helps developers implement event-driven applications. At the same time, any of the distributed systems responsibilities that were previously part of the application layer are moving to the infrastructure layer, whether that is Kubernetes, proxies, or the Linux kernel through eBPF. But overall, the trend shown is accurate, and the focus of CNCF projects continues to be on operating software rather than creating it. The good news is there are new projects such as Dapr and others targeting developers and focused on implementing applications that fit into the cloud native landscape.
Next, we will look into three concrete use cases where Kubernetes is becoming the de facto standard for provisioning and operating applications, whereas Dapr enables developers to implement such cloud native applications and consume the infrastructure in a cloud native way. These use cases demonstrate how Dapr complements Kubernetes and improves developers' productivity the same way Kubernetes improves operation teams' productivity.
Create and operate on-cluster applications
Today the Kubernetes API is the most popular way of deploying and running distributed systems. Containers and Kubernetes allow us to define and enforce application resource constraints. The Pod abstraction with init containers, and sidecars, offers lifecycle guarantees. Health check APIs offer the ability to detect and recover from transient runtime failures. There are declarative deployments, rollbacks, and policy-driven application placement. All that allows Ops to automate the deployment and the management of a large number of workloads, but what is in it for developers?
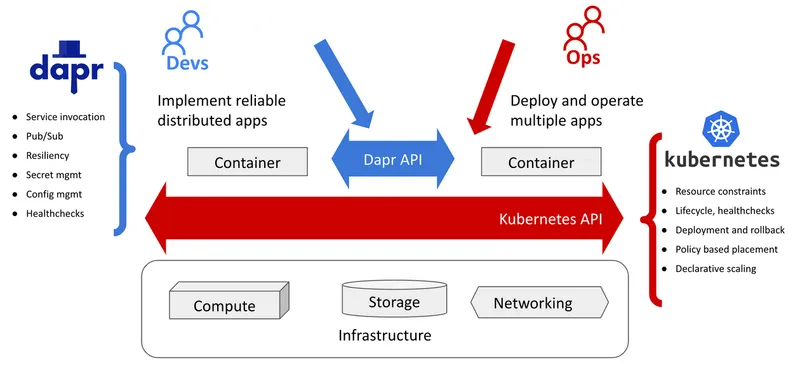
Dapr helps Devs implement distributed apps that Ops can run on Kubernetes
Developers can use Kubernetes service discovery, but that lacks network resiliency features such as retries, timeouts, and circuit breakers. There are ConfigMaps, and Secrets, but they lack dynamic updates, and fine-grained access control. Kubernetes has StatefulSet, but no APIs for accessing that state. There are Kubernetes health checks, but it won't apply for egress connections when consuming from a queue for example. There is nothing in Kubernetes to help with implementing event-driven applications.
This is where Dapr comes in. Dapr addresses these limitations and gives the same productivity to developers that Kubernetes gives to operations. Kubernetes helps operations run applications by abstracting the infrastructure. Dapr helps developers implement these applications and connect them in a reliable way. Dapr has service invocation and Pub/Sub API that help applications written in any language to interact reliably on dynamic cloud infrastructure. It has state management, configuration, secret and other APIs that help developers implement applications and consume the infrastructure through common and reusable patterns.
Provision and consume off-cluster resources
Kubernetes can manage on-cluster applications well. But these on-cluster applications need and depend on off-cluster resources, such as databases, document stores, message queues, and tens of other cloud services. And if you are already using K8s for operating applications, that means you are used with the YAML syntax, with the declarative notion of defining the desired resource state. And if you are using tools and practices such as infrastructure as code and GitOps for automation, then you can use Kubernetes API to manage external resources too. This allows Kubernetes to be the single 'source of truth' for a resource's desired state, not only for on-cluster containers but also off-cluster resources. And today there are such Kubernetes operators such as AWS Controller for Kubernetes, Azure Service Operator, Google Config Connector, and CNCF projects like Crossplane that use Kubernetes CRDs to manage external resources. But the responsibilities of these tools end after managing the lifecycle of the external resource and do not extend into binding to applications running in the Kubernetes data plane. Typically these operators have a mechanism for adding the coordinates of the external resources and access mechanism into a configmap, secret or a CRD. But the actual binding from the application to the resource using the specific protocols is left to developers to deal with. Again.

Dapr helps Devs consume 3rd party service that Ops provision through Kubernetes
This is where Dapr comes to help Developers. Dapr bindings help developers connect applications with external resources regardless of the language your application is using. Provisioning external resources is half of the story. Dapr helps you consume that infrastructure from the application. And does it in a consistent way by adding resiliency, tracing, security, and does it in a cloud native way through APIs and sidecars rather than embedding hard-to-upgrade libraries into the applications.
Develop and orchestrate multi-cluster applications
We have seen how Kubernetes is used to manage applications on a cluster and also used to manage resources external to the cluster. There is one more trend in using Kubernetes APIs, and that is for managing applications on multiple remote clusters.
Today organizations have to deploy applications into multiple data centers, clouds, and Kubernetes clusters for a variety of reasons, such as scale, application and data locality, isolation, and whatnot. The physical boundaries of a Kubernetes cluster don't always conform to the desired application boundaries. Very often the same application or a fleet of applications has to be deployed into multiple clusters which require multi-cluster deployments and orchestration. There are many projects and services that let you operate applications on multiple clusters, such as Azure Arc, Google Anthos, Red Hat Advanced Cluster Manager, Hypershift, and projects such as kcp.io. These projects offer a unified user interface, dashboards, alerts, logs, policies, and access control to multiple clusters. Most of them do it by offering Kubernetes API as the control plane, and each cluster as a data plane. So that you can use consistent operations, and security, compliance models you can integrate your DevOps toolkit.
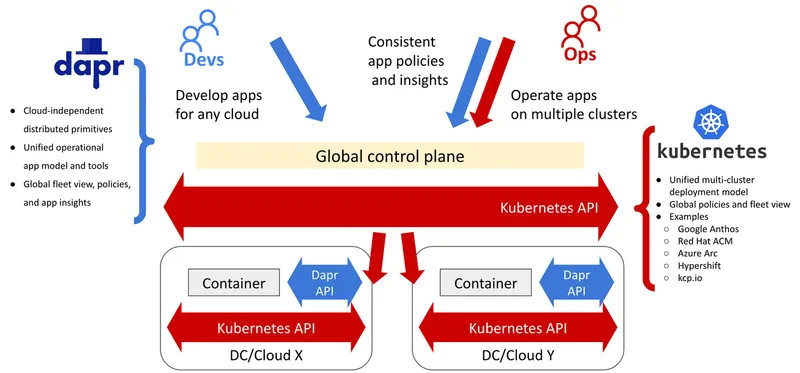
Dapr helps Devs create multi-cloud applications that Ops can operate through Kubernetes APIs
What Dapr can help in this scenario is create multi-cloud applications that can run and interact with any cloud environment. Packaging and running applications on different cloud environments is again half of the story. Typically applications running in a cloud environment have to consume services local to that cloud environment and Dapr enables that. Typically, different cloud providers offer different abstractions, patterns and tools for solving the same problem which are not transferable and reusable in different environments. For example, Azure has Event Grid, AWS offers EventBridge, and GCP has Eventarc for creating event-driven applications. Each of these services has a unique learning curve, and coupling with the cloud provider. Dapr pub/sub API on the other hand, provides generic asynchronous building blocks that can be used for creating event-driven applications for any cloud and on-premise.
In a multi-cloud scenario, Dapr APIs act as unifying building blocks enabling developers to create cloud-independent solutions, and also enabling Ops teams to apply resiliency policies and get metrics, traces from the unified cloud-independent application runtime. Services such as Diagrid Conductor, can help operate Dapr on multiple cloud environments. All of that makes Dapr an ideal complement for developers creating multi-cloud applications, and Ops operating these applications.
Characteristics of ubiquitous cloud native APIs
Kubernetes has become more than a container orchestrator. It can manage on-cluster, off-cluster, and multi-cluster resources. It is a generic and extensible operational model for managing many kinds of resources. Its declarative YAML API and asynchronous reconciliation process has become synonymous with the resource orchestration paradigm. Its CRDs and Operators have become common extension mechanisms for merging domain knowledge with distributed systems.
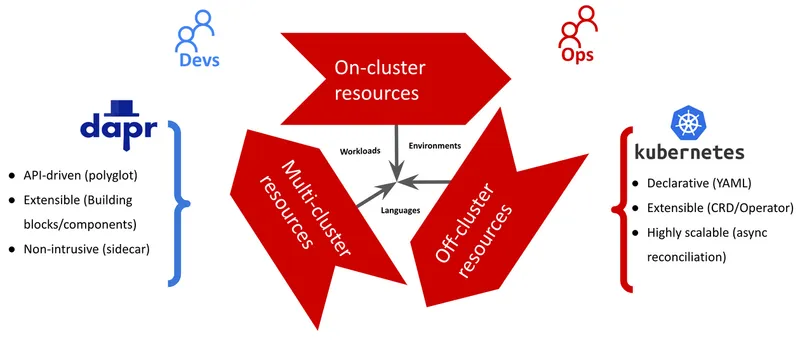
Characteristics of Kubernetes and Dapr APIs
Dapr is built on the same principles and foundation as Kubernetes. Dapr offers its capabilities over well-defined APIs called building blocks. These APIs operate on the ubiquitous HTTP and gRPC protocols making them polyglot and universally accessible from any language or environment. Dapr capabilities are growing constantly with the addition of new building blocks, such as the more recent distributed lock API, and proposals for content store, and workflow API. Dapr capabilities are also extending through addition of new implementations of the building blocks currently over 100 and growing.
This post is based on a talk I gave at Dapr Community Day in Detroit. Follow me at @bibryam and @diagridio to see my journey of using Dapr and building Diagrid Cloud, or shout out any thoughts and comments you have.
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.


