Dapr For Java Developers
In this short article, we will look into how the Dapr project can help Java developers not only to implement best practices and distributed patterns out of the box but also to reduce the application’s dependencies and the amount of knowledge required by developers to code their applications.
Mauricio Salatino
Staff Software Engineer
Coding Java applications for the cloud requires not only a deep understanding of distributed systems, cloud best practices, and common patterns but also an understanding of the Java ecosystem to know how to combine many libraries to get things working.
Tools and frameworks like Spring Boot have significantly impacted developer experience by curating commonly used Java libraries, for example, logging (Log4j), parsing different formats (Jackson), serving HTTP requests (Tomcat, Netty, the reactive stack), etc. While Spring Boot provides a set of abstractions, best practices, and common patterns, there are still two things that developers must know to write distributed applications.
First, they must clearly understand which dependencies (clients/drivers) they must add to their applications depending on the available infrastructure. For example, understand which database or message broker they need, and what driver or client they need to add to their classpath to connect to it. Secondly, they must know how to configure that connection, the credentials, connection pools, retries, and other critical parameters for the application to work as expected. Understanding these configuration parameters pushes developers to know how these components (databases, message brokers, configurations stores, identity management tools) work to a point that goes beyond their responsibilities of writing business logic for their applications.
Learning best practices, common patterns, and how a large set of application infrastructure components work is not bad, but it takes a lot of development time out of building important features for your application.
In this short article, we will look into how the Dapr project (https://dapr.io) can help Java developers not only to implement best practices and distributed patterns out of the box but also to reduce the application’s dependencies and the amount of knowledge required by developers to code their applications.
We will be looking at a simple example that you can find here: https://github.com/salaboy/pizza
This Pizza Store application demonstrates some basic behaviors that most business applications can relate to. The application is composed of three services that allow customers to place pizza orders in the system. The application will store orders in a database, in this case, PostgreSQL, and use Kafka to exchange events between the services to cover async notifications.
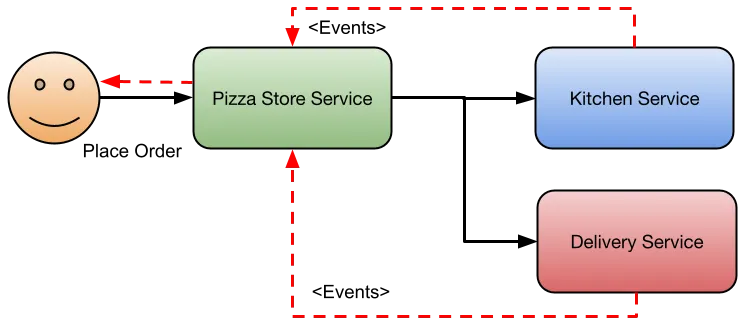
All the asynchronous communications between the services are marked with red dashed arrows. Let’s look at how to implement this with Spring Boot and then let’s add Dapr.
The Spring Boot way
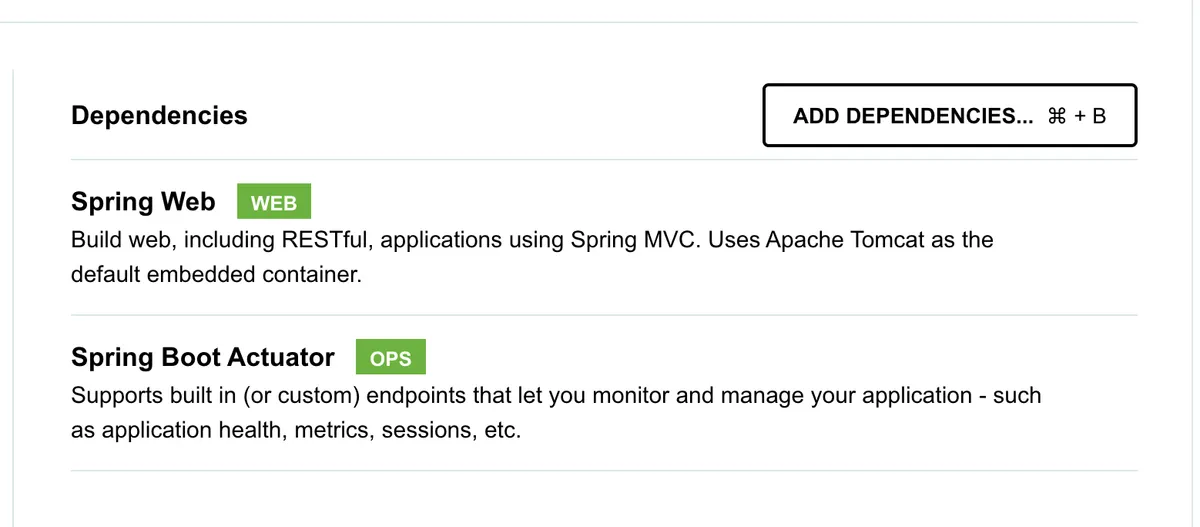
Using Spring Boot, developers can create these three services and start writing the business logic to process the order placed by the customer. Spring Boot Developers can use http://start.spring.io to select which dependencies their applications will have. For example, with the Pizza Store Service, they will need Spring Web (to host and serve the FrontEnd and some REST endpoints), but also the Spring Actuators extension, if we aim to run these services on Kubernetes.
But as with any application, if we want to store data, we will need a database/persistent storage, and we have many options to select from. If you look into Spring Data, you can see that Spring Data JPA provides an abstraction to SQL (relational) databases.
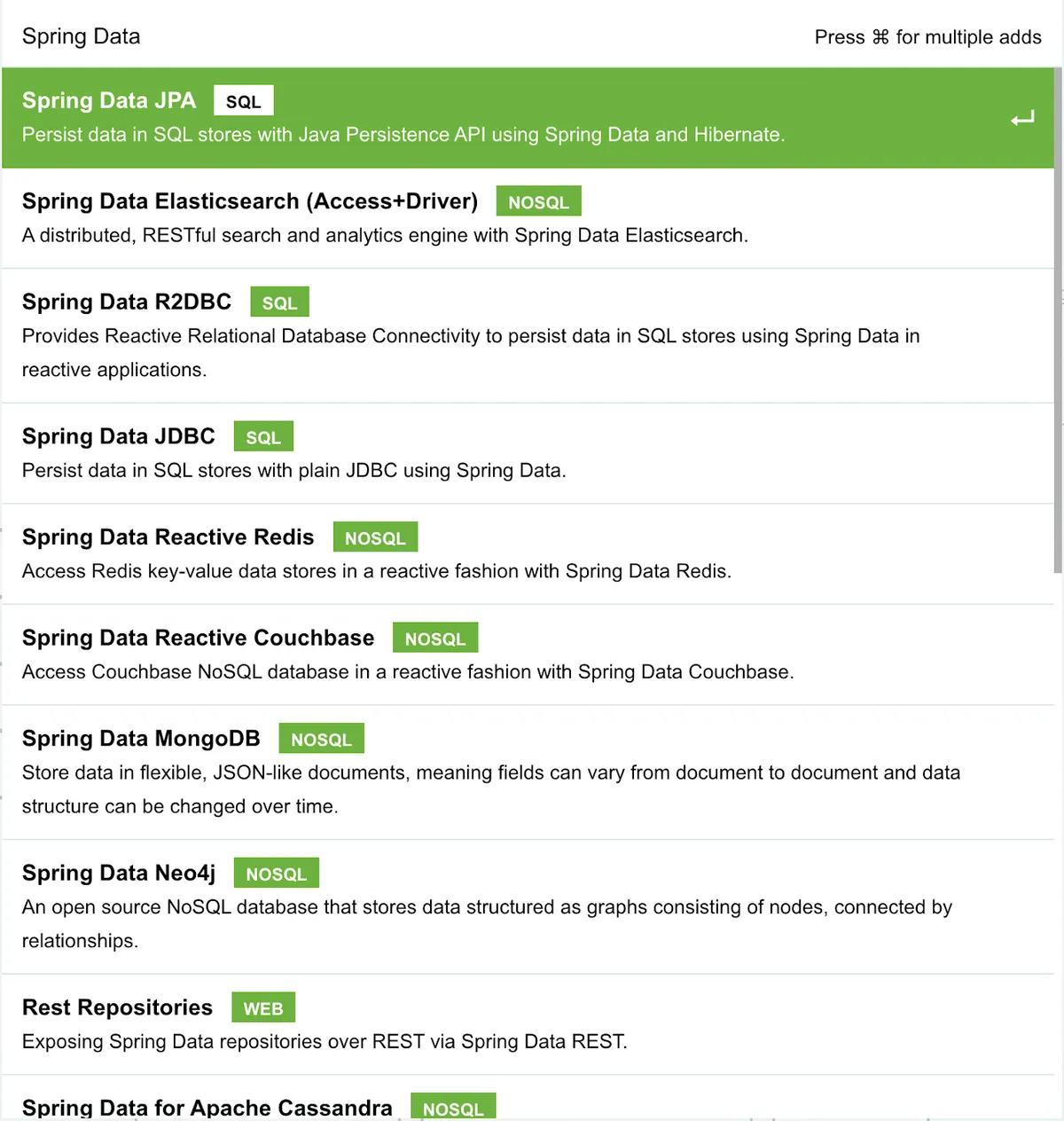
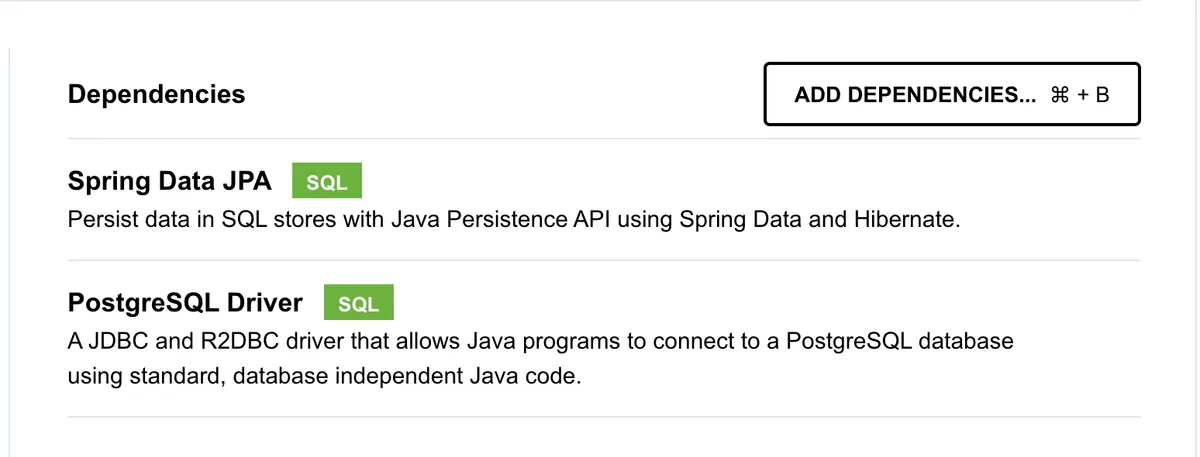
As you can see in the previous screenshot, there are also NoSQL options and different layers of abstractions here, depending on what your application is doing. If you decide to use Spring Data JPA, you are still responsible for adding the correct database Driver to the application classpath. In the case of PostgreSQL you can also select it from the list.
We face a similar dilemma if we think about exchanging asynchronous messages between the application’s services. There are too many options:
Because we are developers and want to get things moving forward, we must make some choices here. Let’s use PostgreSQL as our database and Kafka as our messaging system/broker.
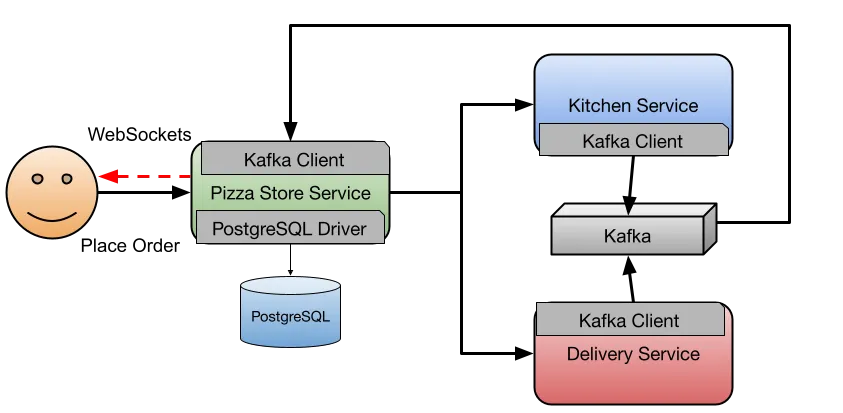
I am a true believer in the Spring Boot programming model, including the abstraction layers and auto-configurations. However, as a developer, you are still responsible for ensuring that the right PostgreSQL JDBC driver and Kafka Client are included in your services classpath. While this is quite common in the Java space, there are a few drawbacks when dealing with larger applications that might consist of tens or hundreds of services.
Application and infrastructure dependencies drawbacks
Looking at our simple application, we can spot a couple of challenges that application and operation teams must deal with when taking this application to production.
Let's start with application dependencies and their relationship with the infrastructure components we have decided to use.
The Kafka Client included in all services needs to be kept in sync with the Kafka instance version that the application will use. This dependency pushes developers to ensure they use the same Kafka Instance version for development purposes. If we want to upgrade the Kafka Instance version, we need to upgrade, which means releasing every service that includes the Kafka Client again. This is particularly hard because Kafka tends to be used as a shared component across different services. Databases such as PostgreSQL can be hidden behind a service and never exposed to other services directly. But imagine two or more services need to store data, if they choose to use different database versions, operation teams will need to deal with different stack versions, configurations, and maybe certifications for each version. Aligning on a single version, say PostgreSQL 16.x, once again couples all the services that need to store or read persistent data with their respective infrastructure components.
While versions, clients, and drivers create these coupling between applications and the available infrastructure, understanding complex configurations and their impact on application behavior is still a tough challenge to solve.
Spring Boot does a fantastic job at ensuring that all configurations can be externalized and consumed from environment variables or property files, and while this aligns perfectly with the 12-factor apps principles and with container technologies such as Docker, defining these configurations parameter values is the core problem. Developers using different connection pool sizes, retry, and reconnection mechanisms being configured differently across environments are still, to this day, common issues while moving the same application from development environments to production.
Learning how to configure Kafka and PostgreSQL for this example will depend a lot on how many concurrent orders the application receives and how many resources (CPU and memory) the application has available to run. Once again, learning the specifics of each infrastructure component is not a bad thing for developers. Still, it gets in the way of implementing new services and new functionalities for the store.
Decoupling infrastructure dependencies and reusing best practices with Dapr
What if we can extract best practices, configurations, and the decision of which infrastructure components we need for our applications behind a set of APIs that application developers can consume without worrying about which driver/client they need or how to configure the connections to be efficient, secure and work across environments?
This is not a new idea. Any company dealing with complex infrastructure and multiple services that need to connect to infrastructure will sooner or later implement an abstraction layer on top of common services that developers can use. The main problem is that building those abstractions and then maintaining them over time is hard, costs development time, and tends to get bypassed by developers who don’t agree or like the features provided.
This is where Dapr offers a set of building blocks to decouple your applications from infrastructure. Dapr Building Block APIs allow you to set up different component implementations and configurations without exposing developers to the hassle of choosing the right drivers or clients to connect to the infrastructure. Developers focus on building their applications by just consuming APIs.
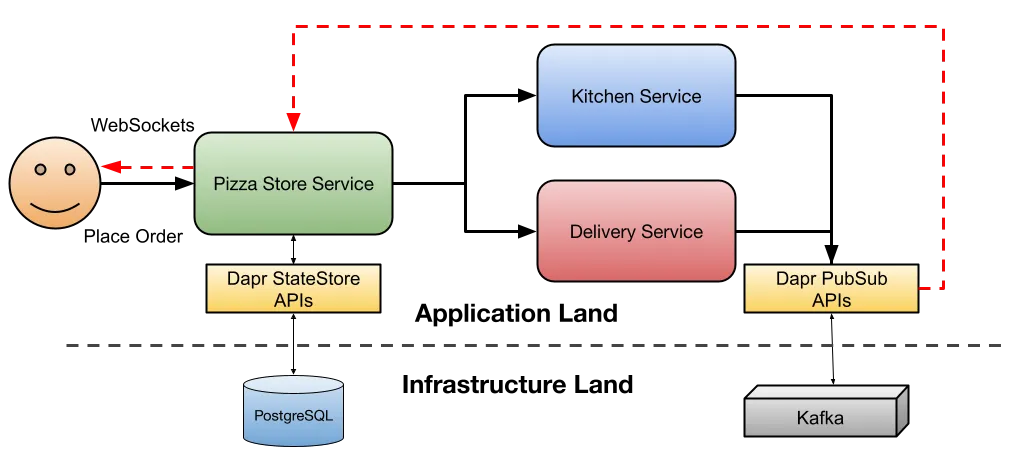
As you can see in the diagram, developers don’t need to know about “infrastructure land” as they can consume and trust APIs to, for example, store and retrieve data and publish and subscribe to events. This separation of concern allows operation teams to provide consistent configurations across environments where we may want to use another version of PostgreSQL, Kafka, or a cloud provider service such as Google PubSub.
Dapr uses the component model to define these configurations without affecting the application behavior and without pushing developers to worry about any of those parameters or the client/driver version they need to use.
Dapr for Spring Boot developers
So, how does this look in practice? Dapr typically deploys to Kubernetes, meaning you need a Kubernetes cluster to install Dapr. Learning about how Dapr works and how to configure it might be too complicated and not related at all to developer tasks like building features.
For development purposes, you can use the Dapr CLI, a command line tool designed to be language agnostic, allowing you to run Dapr locally for your applications. I like the Dapr CLI, but once again, you will need to learn about how to use it, how to configure it, and how it connects to your application.
As a Spring Boot developer, adding a new command line tool feels strange, as it is not integrated with the tools that I am used to using or my IDE. If I see that I need to download a new CLI or if I depend on deploying my apps into a Kubernetes cluster even to test them, I would probably step away and look for other tools and projects. That is why the Dapr community has worked so hard to integrate with Spring Boot more natively.
These integrations seamlessly tap into the Spring Boot ecosystem, without adding new tools or steps to your daily work. Let’s see how this works with concrete examples.
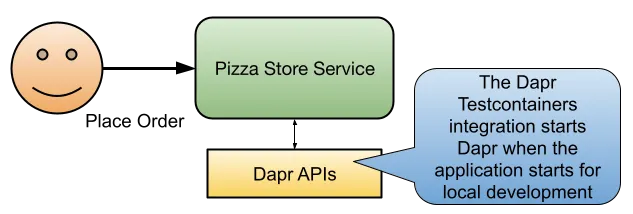
You can add the following dependency in your Spring Boot application that integrates Dapr with Testcontainers.
<dependency><br> <groupId>io.diagrid.dapr</groupId><br> <artifactId>dapr-spring-boot-starter</artifactId><br> <version>0.10.7</version><br></dependency>
https://github.com/salaboy/pizza/blob/main/pizza-store/pom.xml#L32
Testcontainers (https://testcontainers.com/ now part of Docker) is a popular tool in Java to work with containers, primarily for tests, specifically integration tests that use containers to set up complex infrastructure.
Our three Pizza Spring Boot services have the same dependency. This allows developers to enable their Spring Boot applications to consume the Dapr Building Block APIs for their local development without any Kubernetes, YAML, or configurations needed.
Once you have this dependency in place, you can start using the Dapr SDK to interact with Dapr Building Blocks APIs, for example, if you want to store an incoming order using the Statestore APIs:
try (DaprClient client = (new DaprClientBuilder()).build()) {<br> client.saveState(STATESTORE_NAME, KEY, order).block();<br>}
Where `STATESTORE_NAME` is a configured Statestore component name, the `KEY` is just a key that we want to use to store this order and `order` is the order that we received from the Pizza Store frontend.
Similarly, if you want to publish events to other services, you can use the PubSub Dapr API, for example, to emit an event that contains the order as the payload, you can use the following API:
try (DaprClient client = (new DaprClientBuilder()).build()) {<br> client.publishEvent(PUBSUB_NAME, PUBSUB_TOPIC, order).block();<br>}
The publishEvent API publishes an event containing the `order` as a payload into the Dapr PubSub component named (PUBSUB_NAME) and inside a specific topic indicated by PUBSUB_TOPIC.
Now, how is this going to work? How is Dapr storing state when we call the saveState() API, or how are events published when we call publishEvent()?
By default, the Dapr SDK will try to call the Dapr API endpoints to localhost, as Dapr was designed to run beside our applications. For development purposes, to enable Dapr for your Spring Boot application, you can use one of the two built-in profiles: DaprBasicProfile or DaprFullProfile.
The Basic profile provides access to the Statestore and PubSub API, but more advanced features such as Actors and Workflows will not work. If you want to get access to all Dapr Building Blocks, you can use the Full profile. Both of these profiles use in-memory implementations for the Dapr components, making your applications faster to bootstrap.
The dapr-spring-boot-starter was created to minimize the amount of Dapr knowledge developers need to start using it in their applications. For this reason, besides the dependency mentioned above, a test configuration is required in order to select which Dapr profile we want to use. Since Spring Boot 3.1.x, you can define a Spring Boot application that will be used for test purposes. The idea is to allow tests to set up your application with all that is needed to test it. From within the test packages (src/test/<package>) you can define a new @SpringBootApplication class, in this case, configured to use a Dapr profile.
@SpringBootApplication<br>public class PizzaStoreAppTest {<br> public static void main(String[] args) {<br> SpringApplication.from(PizzaStore::main)<br> .with(AppTestConfiguration.class)<br> .run(args);<br> }<br><br><br> @ImportTestcontainers(DaprBasicProfile.class)<br> static class AppTestConfiguration {}<br>}
As you can see, this is just a wrapper for our PizzaStore application, which adds a configuration that includes the DaprBasicProfile. With the DaprBasicProfile enabled, whenever we start our application for testing purposes, all the components that we need for the Dapr APIs to work will be started for our application to consume. If you need more advanced Dapr setups, you can always create your domain-specific Dapr profiles.
Another advantage of using these test configurations is that we can also start the application using test configuration for local development purposes by running `mvn spring-boot:test-run`
You can see how Testcontainers is transparently starting the `daprio/daprd` container. As a developer, how that container is configured is not important as soon as we can consume the Dapr APIs.
I strongly recommend you check out the full example here: https://github.com/salaboy/pizza, where you can run the application on Kubernetes with Dapr installed or start each service and test locally using Maven.
If this example is too complex for you, I recommend you to check these blog posts where I create a very simple application from scratch:
- Using the Dapr StateStore API with Spring Boot: https://www.salaboy.com/2023/12/07/back-to-basics-dapr-statestore-and-spring-boot/
- Deploying and configuring our simple application in Kubernetes: https://www.salaboy.com/2023/12/14/back-to-basics-apis-to-rule-them-all-dapr-on-kubernetes-2/
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.


